If anyone tells you with certainty what’s going to happen to Power BI jobs because of LLMs, they fall into one of two categories:
- Bullshitters
- People who fired a consultant because AI helped them successfully do it instead.
I fall into the former category and I’m going to impart all of my great wisdom in this blog post. But be aware than anyone who tells you what will happen more than 3-6 months out is bullshitting you. We are all just guessing and extrapolating.
Enough with the pithy cliches
I’m pretty tired of the “AI won’t take your job, but someone with AI will” cliche. I get it, it makes sense. But it’s also fairly reductionist. AI doesn’t need to replace you to make you lose your job. And learning to use AI effectively isn’t a guarantee that you’ll keep it.
Some jobs are just gone. Chegg was a company that helped students cheat on homework and ChatGPT was a death knell for them. StackOverflow was in decline for a while but ChatGPT accelerated it. No amount of AI will help those employees keep their prior jobs. Those jobs are gone.
Other jobs may go away from efficiency gains. Historically, if a technology causes 10 workers to be 11% more efficient, what does the company do? They fire one of the workers. We aren’t getting a utopia with 4 day workweeks, folks. That’s not how capitalism works.
There are exceptions, however. ATMs make bank branches cheaper to run, so the number of branches proliferated, and the number of bank employees increased. The invention of the digital spreadsheet led to huge growth in the field and a whole new category of worker.
Sometimes making something cheaper or easier to access increases demand. See Jevon’s Paradox as AI enthusiasts like to spout. But just as often it doesn’t.
I don’t have any reason to believe that AI efficiencies will lead to increased demand for BI developers, I just don’t. It’s far, far more likely that the things AI will be able to do increases the demand for self-service greatly and the things it can’t do will lead to stable demand for those tasks.
People will be able to easily build and prototype the reports they need themselves, but making sure they are building the right thing and validating the business logic will remain difficult and needed. Get good at that.
Bi-athletes
BI developers are bi-athletes. I compare us to chessboxers (yes that’s a real thing) or people competing in a biathalon (which is completely different than a triathalon or decathalon? WTH). On the spectrum of coder to designer, BI developers sit smack dab in the middle. Users never know what they want and we have to tease it out of them.
We are therapists for people’s data.
And here’s the key thing. Those same skills make us well-positioned to handle what is coming. It’s time to lean into the therapy part because the coding part is becoming less important. Where we sit on that spectrum is shifting.
You thought you were a boxer but you need to get better at chess. You thought you were a skier but you need to get better at sharpshooting. You thought you were a coder but you need to get better at design and iteration.
The bitter reversal for BI developers
Every skill and attitude gap you’ve ever complained about in your users or customers is going to swing right back around and hit you in the face like a karmic boomerang.
- Users don’t know what they want? You don’t know what you want AI to do.
- Users change their mind when they see the report? You will change your mind when you see what slop AI codes for you.
- Users aren’t good at writing specs and requirements? You aren’t good at writing specs and requirements.
Every single skill you wish your users had when you try to do work for them, those are skills that you should be improving on a daily basis. All of those “soft” skills just got a lot less soft and a lot more critical to your job 5 years from now. Get cracking.
Ethan Mollick just put out a fascinating blog post about his “vibe entrepreneurship” course for MBA students, and everything resonates to me. Everyone who wants to use AI will benefit from classical communication and management skills.
Why Power BI and Fabric are safer for longer
Based on my experience with vibe coding a lot of things, I think a lot of an LLM agent’s success depends on these 4 factors:
- The ability to safely make changes. Source control, workspace branches, containers, etc.
- The ability to automatically verify the results. Compilers, typed languages, unit tests, integration tests, etc.
- The ability to automatically receive feedback. Compiler warnings, type check warnings, language linters, git commit hooks, etc.
- Reinforcement Learning with Verifiable Rewards. Much of the modern improvement in LLM reasoning comes from RLVR and fine tuning a model based on real problems and measurable success. That’s easy to do for Python, hard to do for Power BI.
When I look at Power BI and Fabric, it just isn’t there yet. Git integration for Fabric has been a sore spot and is on-going. The modeling side of Power BI is rock-solid but the PBIR metadata is not and there isn’t a decade of PBIP support.
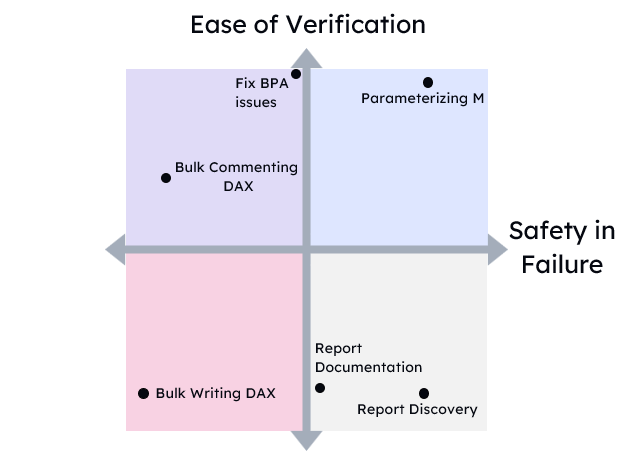
I think folks in the Power BI and Fabric space are going to be safer for longer than say the backend coding space. But this will be unevenly distributed across types of tasks. Even today with the Power BI modeling MCP server, there are some tasks that are trivial to hand off to an AI and some that are very dangerous. Aim for the upper right quadrant here. Expect more tasks to move in that direction.
Unfounded predictions for 2026
If I had to guess where we will be by the end of 2026, and I am guessing, I think that the shockwaves that were sent out in December 2025 by Claude Opus 4.5 and ChatGPT 5.2 Codex will finally reach the shores of Power BI and Fabric by December 2026 at the latest.
Change is coming.
Now, if you are feeling overwhelmed, scared, or frustrated, I hear you. I feel you. My advice is don’t try to keep up. Try to keep situational awareness by picking a few bloggers or podcast to follow and try to learn by osmosis.
It is much, much better for you to try to build something with AI for 15 minutes every day than it is to try to cram it in over a long weekend. Treat this like you would learn a new language or a new culture.
No one learns a language by binging. No one ever feels FOMO because their friends are learning Danish.
Although I will be learning Danish because of a new job I’m starting next week, so maybe you should feel a little FOMO 😜.