On some level, I’ve started to hate writing these blog posts.
The original intent was to show the ups and downs of being a consultant, inspired by Brent Ozar’s series on the same thing. There’s a huge survivorship bias in our field, only the winners talk about self-employment, and the LinkedIn algorithm encourages only Shiny Happy People. But when you enter the third consecutive year of the 3 most difficult years of your career, you start to wonder if it might be a you problem. So here we go.
Pivoting my business
Two years ago, Pluralsight gave all authors a 25% pay cut and I knew I needed to get out. I reached out to everyone I knew who sold courses themselves for advice. I’m deeply grateful to Matthew Roche, Melissa Coates, Brent Ozar, Kendra Little, and Erik Darling for the conversations that calmed my freak out at the time.
One year ago, I learned that I can’t successfully make content my full-time job while also successfully consulting. Consulting work tends to be a lot of hurry-up-and-wait. Lots of fires, emergencies, and urgencies. No customer is going to be happy if you tell them the project needs to wait a month because you have a course you need to get out. Previously with Pluralsight I was able to make it work because they scoped the work, so it was more like a project. Not so when hungry algos demand weekly content.
So, I cut the consulting work to a bare minimum. Thankfully, I receive money enough from Pluralsight royalties that even with the cut we never have to worry about paying the mortgage. However, it’s nowhere close to covering topline expenses. At the beginning pandemic, $6k/mo gross revenue was what we needed to live comfortably (Western PA is dirt cheap). After the pandemic, I hired a part time employee, inflation happened, and I pay for a lot more subscriptions, like Teachable and StreamlineHQ, so that number is closer to $9k/mo now.
I can confirm that I have not and never will make $9k/mo or more from just Pluralsight. My royalties overall have been stagnant or even gone down a bit since the huge spike upwards in early 2020. So it’s not enough to live off of alone.
Finally, after a lot of dithering in the 2023, I decided to set a public and hard deadline for my course. We were launching in February 2024 hell or high water. I launched with 2 out of 7 modules and it was a huge success, making low four figures. I’m grateful to everyone who let me on to their podcast or livestream, which provided a noticeable boost in sales.
Unfortunately, I had a number of projects right after launch, taking a lot of my focus. I also found out that this content was much much more difficult than the Pluralsight content I was used to. There was no one from curriculum to hand me a set of course objectives to build to. No one to define the scope and duration of the course.
What’s worse, the reason there is a moat and demand for Power BI performance tuning content is almost no one talks about it. You have dozens of scattered Chris Webb blog posts, a book and a course from SQL BI, a course by Nikola Illic, and a book by Thomas LeBlanc and Bhavik Merchant. And that’s about it?
I thought I was going to be putting out a module per week, when in reality I was doing Google searches for “Power BI Performance tuning”, opening 100 tabs, and realizing I had signed myself up for making 500 level internals content. F*ck.
A summer of sadness
All at the same time I was dealing with burnout. My health hadn’t really improved any over the past 3 years and I was finding it hard to work at all. I was anxious. I couldn’t focus. And the content work required deep thought and space and I couldn’t find any. I felt a sense of fragility where I might have a good week the one week and then have a bad nights sleep and derail the next week.
I hadn’t made any progress on my course and a handful of people reached out. I apologized profusely, offered refunds, and promised to give them free access to the next course. If you were impacted by my delays, do please reach out.
In general, I decided that I needed to keep cutting things. I tried to get any volunteer or work obligations off my plate. The one exception is I took on bringing back SQL Saturday Pittsburgh. With the help of co-organizers like James Donahoe and Steph Bruno, it was a lot of work but a big success. I’m very proud of that accomplishment.
Finally turning a corner
I think I finally started turning a corner around PASS Summit. It was refreshing to see my friends and see where the product is going. Before Summit, I had about 3.5 modules done. In the period of a few weeks I rushed to get the rest done. This was also because I really wanted to get the course finished for a Black Friday sale.
The sale went well, making mid three figures. Not enough to live on, but proof that there is demand and it’s worth continuing instead of burning it all down and getting a salaried job. Still, I recently had to float expenses on a credit card for the first time in years, so money is tighter than it used to be. Oh the joys of being paid NET 30 or more.
Immediately after Black Friday, I went to Philadephia to delivery a week long workshop on Fabric and Power BI. The longest training I had ever given before was 2 days. The workshop went well, but every evening I was rushing back to my hotel room to make more content. You would think that 70 slides plus exercises would last a whole day, but no, not even close.
Now I’m back home and effectively on vacation for the rest of the year and it’s lovely. I’m actually excited to be working on whatever whim hits me, setting up a homelab and doing Fabric benchmarks. It’s the first time I’ve done work for fun in years.
I’m excited for 2025 but cautious to not over-extend myself.
First, a disclaimer: I am not a data engineer, and I have never worked with Fabric in a professional capacity. With the announcement of Fabric SQL DBs, there’s been some discussion on whether they are better for Power BI import than Lakehouses. I was hoping to do some tests, but along the way I ended up on an extensive Yak Shaving expedition.
I have likely done some of these tests inefficiently. I have posted as much detail and source code as I can and if there is a better way for any of these, I’m happy to redo the tests and update the results.
Part one focuses on loading CSV files to the files portion of a lakehouse. Future benchmarks look at CSV to delta and PBI imports.
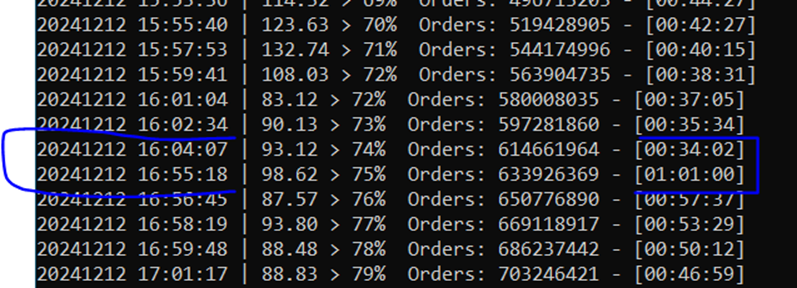
In this benchmark, I generated ~2 billion rows of sales data using the Contoso data generator on a F8as_v6 virtual machine in Azure with a terabyte of premium SSD. This took about 2 hours (log) and produced 194 GB of files, which works out to about $1-2 as far as I can tell (assuming you shut down the VM and delete the premium disk quickly). You could easily do it for cheaper, since it only needed about 16 GB of RAM.
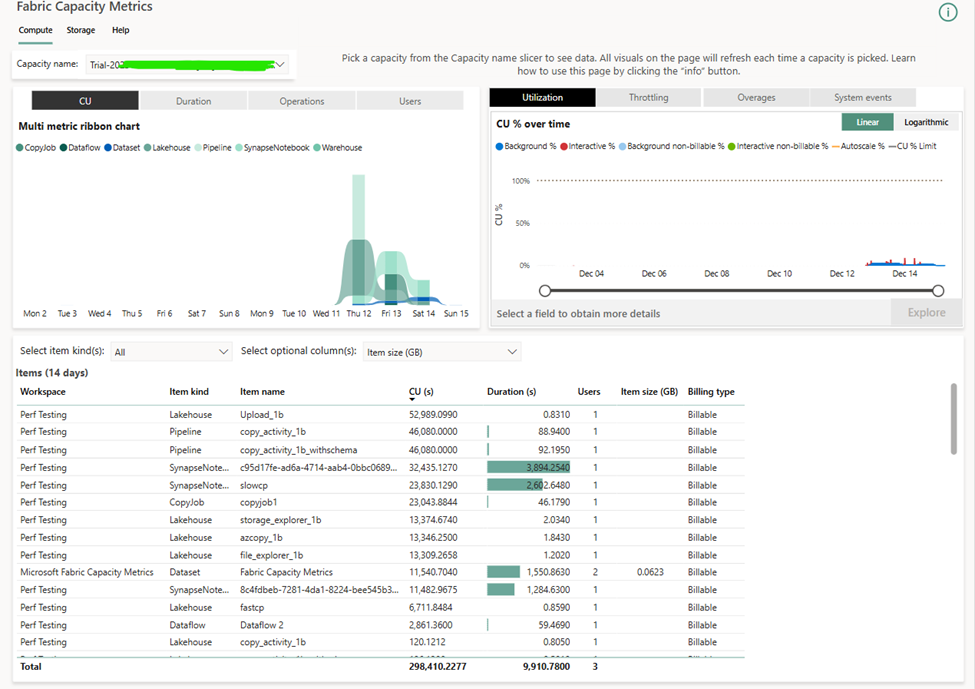
In general, I would create a separate lakehouse for each test and a separate workspace for each run of a given test. This was tedious and inefficient, but the easiest way to get clean results from the Fabric Capacity Metrics app without automation or custom reporting. I tried to set up Will Crayger’s monitoring tool but ran into some issues and will be submitting some pull requests.
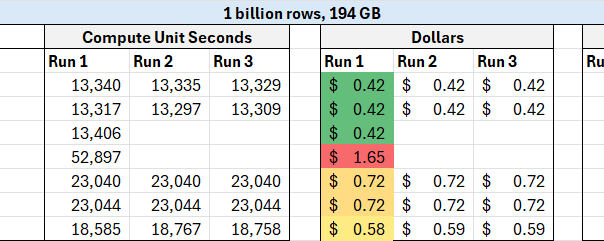
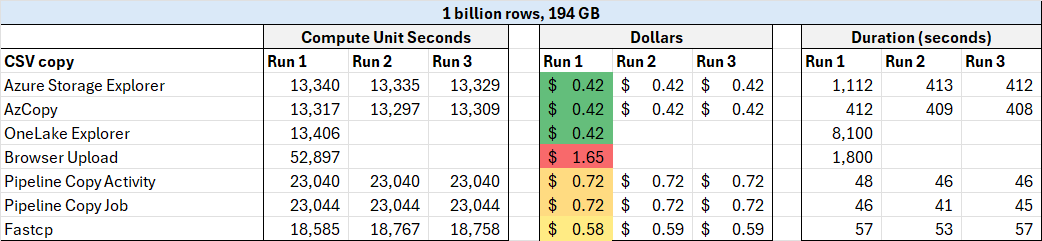
To get the CU seconds, I copied from the Power BI visual in the metrics app and tried to ignore incidental costs (like creating a SQL endpoint for a lakehouse). To get the costs, I took the price of an F2 in East US 2 ($162/mo), divided it by the number of CUs (2 CUs), and divided by the number of seconds in 30 days (30*24*60*60). This technically overestimates the costs for months with 31 days in them.
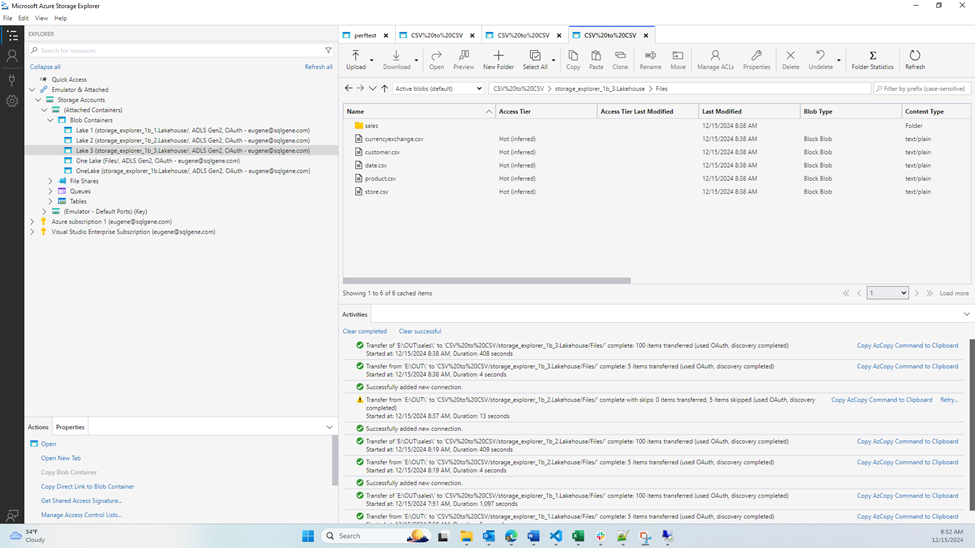
External methods of file upload (Azure Storage explorer, AZ Copy, and OneLake File Explorer) are clear winners, and browser based upload is a clear loser here. Do be aware that external methods may have external costs (i.e. Azure costs).
Data Generation process
As I mentioned, I spun up a beefy VM and ran the Contoso Data Generator, which is surprisingly well documented for a free, open source tool. You’ll need .NET 8 installed to build and run the tool. The biggest thing is that you will want to modify the config file if you want a non-standard size for your data. In my case, I wanted 1 billion rows of data (OrdersCount setting) and I limited each file to 10 million rows of data (CsvMaxOrdersPerFile setting). This technically will produce 1 billion orders so 2 actually billion sales rows when order header is combined with order lineitem. This produced 100 sales files of about 1.9 GB each.
I was hoping the temporary SSD drive included with Azure VMs was going to be enough, but it was ~30 GB if I recall, not nearly big enough. So instead, I went with Premium SSD storage instead, which has the downside of burning into my Azure Credits for as long as it exists.
One very odd note, at around %70 percent complete, the data generation halted for no particular reason for about 45 minutes. It was only using 8 GB of the 32 GB available and was completely idle with no CPU activity. Totally bizarre. You can see it in the generation log. My best theory is it was waiting for the file system to catch up.
Lastly, I wish I was aware of how easy it was to expand the VM disk image when you allocate a terabyte of SSD. Instead, I allocated the rest of the SSD as a E drive. It was still easy to generate the data, but it added needless complication.
Thanks to James Serra’s recent blog post, I had a great starting point to identify all the ways to load data into Fabric. That said, I’d love it if he expanded it to full paragraphs since the difference between a copy activity and a copy job was not clear at all. Additionally, the Contoso generator docs list 3 ways to load the data, which was also a helpful starting point.
I stored the data on a container on Azure Blob storage with Hierarchical Namespaces turned on and the it said the Data Lake Storage endpoint is turned on by default, making it Azure Data Lake Storage Gen 2? At least I think it does, but I don’t know for sure and I have no idea how to tell.
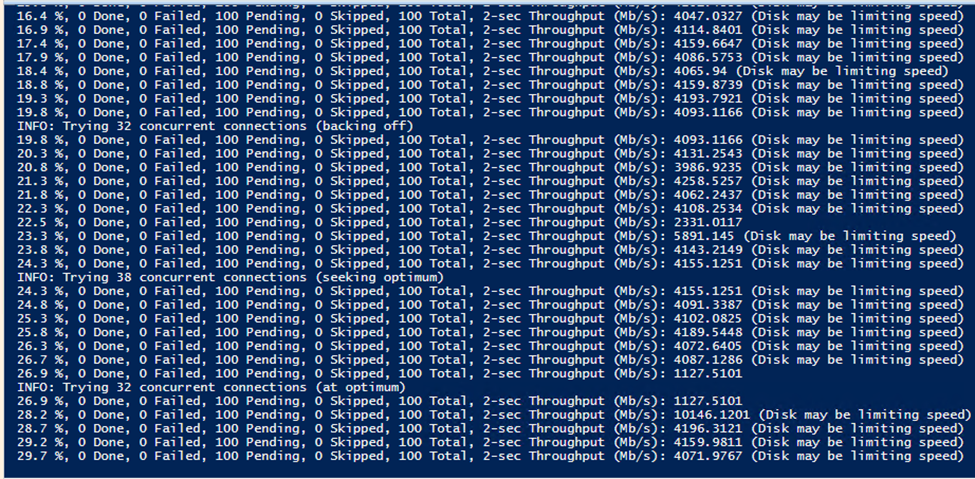
The Azure Storage Explorer is pretty neat and I was able to get it running without issue or confusion. Here are the docs for connecting to OneLake, it’s really straightforward. I did lose my RDP connection during all three of the official tests, because it maxed out IO on the disk which was the OS disk. I probably should have made a separate data disk, UGH. Bandwidth would fluctuate wildly between 2,000 and 8,000 Mbps. I suspect a separate disk would go even faster. The first time I had tested it, I swear it stayed at 5,000 Mbps and took 45 seconds, but I failed to record that.
It was also mildly surprising to find there was a deletion restriction for workspaces with capital letters in the name. Also, based on the log files in the .azcopy folder, I’m 95% sure the storage explorer is just a wrapper for AzCopy
AzCopy is also neat, but much more complicated, since it’s a command line program. Thankfully, Azure Storage Explorer let me export the AzCopy commands so I ran that instead of figuring it out myself or referencing the Contoso docs.
If you go this route, you’ll get a message like “To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ABCDE12FG to authenticate”. This authentication could be done from any computer, not just the VM, which was neat.
I got confirmation from the console output that the disk was impacting upload speeds. Whoops.
The OneLake File Explorer allows you to treat your OneLake like it was a OneDrive Folder. This was easy to set up and use, with a few minor exceptions. First, it’s not supported on Windows Server and in fact I couldn’t find a way at all to install the MISX file on Windows Server 2022. I tried to follow a guide to do that, but no luck.
The other issue is I don’t know what the heck I’m doing, so I didn’t realize I could expand the C Drive on the default image. Instead, I allocated the spare SSD space to the F drive. But when I tried to copy the files to the C drive, there wasn’t enough space, so I had them in 3 batches of 34 files.
This feature is extremely convenient but was challenging to work with at this scale. First, because it’s placed under the Users folder, both Windows search index and anti-virus were trying to scan the files. Additionally, because my files were very large, it would be quite slow when I deallocated files to free up space.
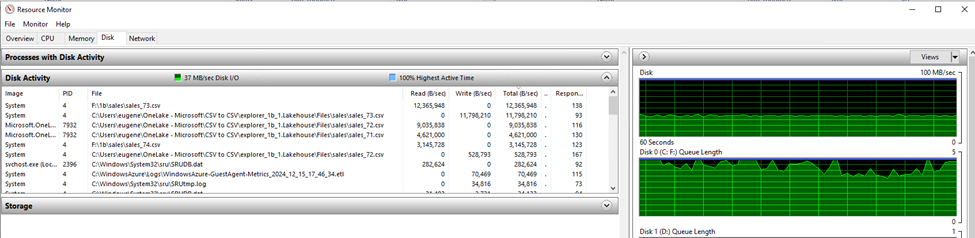
Oddly, the first batch stayed around 77 MB/s, the second was around 50 MB/s, and the last batch tanked to a speed of 12 MB/s, more than doubling the upload time. Task Manager showed disk usage at 100%, completely saturated. I tried taking a look at resource monitor but I didn’t see anything unusual. Most likely it’s just a bad idea to copy 194 GB from one drive back to itself, while deallocating the files in-between.
Browser-based file upload was the most expensive in terms of CUs but was very convenient. It was shockingly stable as well. I’ve had trouble downloading multiple large files with Edge/Chrome before, so I was surprised it uploaded one hundred 2 GB files without issue or error. It took 30 minutes, but I expected a slowdown going via browser so not complaints here. Great feature.
Setting up a pipeline copy activity to read from Azure Blob storage was pretty easy to do. The biggest challenge was navigating all the options without feeling overwhelmed.
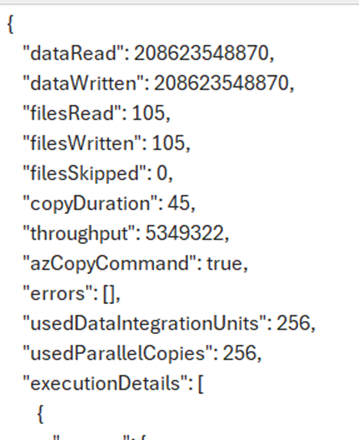
Surprisingly, there was no measurable difference in CUs between schema agnostic (binary) copy and not schema agnostic (CSV validation) copy. However, all the testing returned the same cost, so I’m guessing the costing isn’t as granular and doesn’t pick up a 2 second difference between runs.
Based on the logs it looks like it may also be using AzCopy because azCopyCommand was logged as true. It’s AzCopy all the way down apparently. The CU cost (23,040) is exactly equal to 2 times the logged copy duration (45 s) times the usedDataIntegrationUnits (256), so I suspect this is how it’s costed, but I have no way of proving it. It would explain why there was no cost variation between runs.
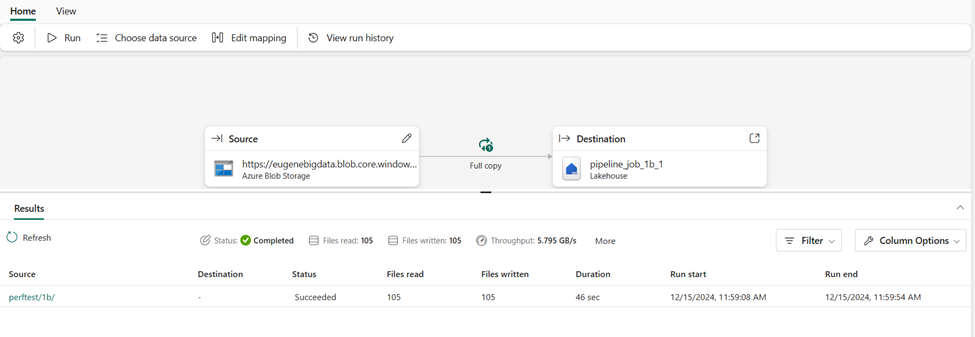
The copy job feature is just lovely. I was confused based on the name how it differed from a copy activity, but it seems to be a simpler way of copying files with fewer overwhelming options and nicer UI that clearly shows throughput, etc. The JSON code also looks very simple. Just wonderful overall.
It is in preview, so you will have to turn it on. But that’s just an admin toggle. Reitse Eskens has a nice blog post on it. My only complaint is I didn’t see a way to copy a job or import the JSON code.
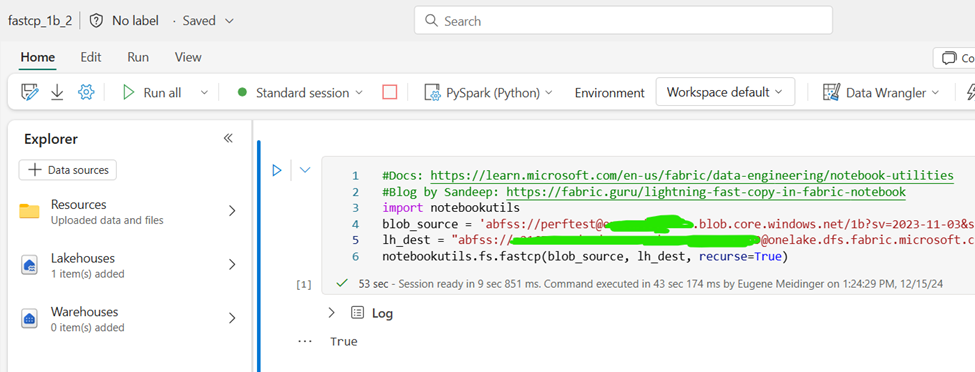
My friend Sandeep Pawar recommended trying fastcp from notbookutils in order to copy files with spark. The documentation is fairly sparse for now, but Sandeep has a short blog post that was helpful. Still, understanding the exact URL structure and how to authenticate was a challenge.
Fastcp is a wrapper for….you guessed it, AzCopy. It seems to take the same time as all the other options running AzCopy (45 seconds) + about 12 seconds for spinning up a Spark session as far as I can tell. Sandeep has told me that it also works in Python for cheaper, but when I ran the same code I got an authorization error.
Overall, I see the appeal of Spark notebooks, but one frustration was that DAX has taught me to press Alt + Enter when I need a newline, which does the exact opposite in notebooks and will instead execute a cell and make a new one.
Learnings and paper cuts
I think my biggest knowledge gap overall was in the precise difference between blob storage and ADLS storage gen 2, as well as access URLS and access methods. Multiple times I tried to generate an SAS key from the Azure Portal and got an error when I tried to use it. Once, out of frustration I copied the one from the export to AzCopy option into my spark notebook to get it to work. Another time I used the generate SAS UI in the storage explorer and that worked great.
Even trying to be aware of all the ways you can copy both CSV files as well as convert CSV to delta is quite a bit to take on. I’m not sure how anyone does it.
My biggest frustration with Fabric right now is around credentials management. Because I had made some different tests, if I searched for “blob”, 3 options might show up (1 blob storage, 2 ADLS).
Twice, I clicked on the wrong one (ADLS) and got an error. The icons and name are identical so the only way you can tell the difference is by “type”.
This is just so, so frustrating. Coming from Power BI, I know exactly where the data connection is because it’s embedded in the semantic model. In OneLake it appears that connections are shared and I have no idea what scope they are shared within (per user, per workspace, per domain?) and I have no idea where to go to mange them. This produces a sense of unease and being lost. It also led to frustration multiple times when I tried to add a lakehouse data source but my dataflow already had that source.
What I would love to see from the team is some sort of clear and easily accessible edit link when it pulls in an existing data source. This would be simple (I hope) and would lead to a sense of orientation, the same way that the settings section for a semantic model has similar links.
If you’ve dealt with Power BI licensing before, Fabric licensing makes sense as an extension of that model plus some new parts around CUs, bursting and smoothing. But what if you are brand new to Fabric, Power BI, and possibly even Office 365?
If you want to get started with Fabric, you need at a bare minimum the following:
Fabric computing capacity. The cheapest option, F2, costs $263 per month for pausable capacity (called Pay-as-you-go) and $156 per month for reserved capacity. Like Azure, prices vary per region.
An Entra tenant. Formerly called Azure Active Directory, Entra is required for managing users and authentication. You will also need an Office 365 tenant on top of that.
Once you have an F2, you can assign that capacity to Fabric workspaces. Workspaces are basically fancy content folders with some security on top of it. Workspaces are the most common way access is provided to content. With the F2 you’ll have access to all non-Power BI fabric objects.
The F2 sku provides 0.25 virtual cores for Power BI workloads, 4 virtual cores for Spark workloads, and 1 core for data warehouse workloads. These all correspond to 2 CUs, also known as compute units. CUs are a made up unit like DTUs for databases or Fahrenheit in America. They are, however, the way that you track and manage everything in your capacity and keep costs under control.
Storage is paid for separately. OneLake storage costs $0.023 per GB per month. You also get X TB of free mirroring storage equal to your SKU level. So F2 gets 2 TB of storage.
There is no cost for networking, but that will change at some point in the future.
Power BI content
If your users want to create Power BI reports in these workspaces, they will need to be assigned a Power BI Pro license at a minimum, which costs $14 per user per month. This applies to both report creators and report consumers. Pro provides a majority of Power BI features.
The features this does not provide are covered by Power BI Premium per User (PPU) licenses, which cost $24 per user per month. These licenses allow for things like more frequent refreshes and larger data models. PPU is a hybrid license because you both license the user as well as assign the content to a workspace set to PPU capacity.
One of the downsides of the PPU model is that they act as a universal receiver of content but not a universal donor. Essentially, the only way for anyone to read reports hosted in a PPU workspace is to have a PPU license. So, you can’t use this as a cheat code to license your report creators with PPU and everyone else with Pro. Nice try.
There is demand for a fabric equivalent, a FPU license, but there is no word on when or if this will happen. Folks estimate this could cost anywhere from $30 to $70 per user per month if we get one.
Finally, if you ramp up to an F64 sku, Power BI content is then included. Users will still need a Fabric Free license. At $5002/mo for F64, this means it’s worth switching over at 358 Pro users or 209 PPU users. Additionally, you unlock all premium features including copilot.
Even if you pay for F64 or higher (or Power BI report server on Prem), any report creators need to be licensed with Power BI Pro for use of that publish button. I cannot understand why Microsoft would charge $5k per month and then charge for publishing on top.
There are also licensing complications for embedding Power BI in a custom application which is outside of the scope of this post. Basically the A and EM SKUs are more restrictive than the F SKUs.
Capacity management
Despite a Fabric SKU providing a fixed number of Capacity Units, Fabric is also intended to be somewhat flexible. Fabric customers like the pricing predictability of Fabric compared to Azure workloads, but because of the sheer number of tools and workloads supported, actual usage can vary wildly compared to when premium capacity was only Power BI reports.
In order to support that, Fabric allows for bursting and smoothing. This is similar to auto-scaling, but not quite. Bursting will provide you with more capacity temporarily during spikey workloads, by up to a factor of 12 in most cases. However, this bursting isn’t free. You are borrowing against future compute capacity. This means it’s possible to throttle yourself by overextending.
Bursting is balanced out by smoothing. Whenever you have exceeded your default capacity, future work is spread out over a smoothing window. This is a 5 minute window for anything a user might see and 24 hours for background tasks. If you are using pay-as-you-go capacity, you’ll see a spike in CUs when you shut down the capacity, as all of this burst debt is paid off all at once instead of waiting for smoothing to catch up.
From what I’ve been told by peers, it’s possible that you can effectively take down a capacity with a rogue Spark notebook by bursting for to long. Essentially that smoothing has to use the full window to catch up. At Ignite 2024 they announced they are working on Surge protection to prevent this