First, a disclaimer: I am not a data engineer, and I have never worked with Fabric in a professional capacity. With the announcement of Fabric SQL DBs, there’s been some discussion on whether they are better for Power BI import than Lakehouses. I was hoping to do some tests, but along the way I ended up on an extensive Yak Shaving expedition.
I have likely done some of these tests inefficiently. I have posted as much detail and source code as I can and if there is a better way for any of these, I’m happy to redo the tests and update the results.
Part one focuses on loading CSV files to the files portion of a lakehouse. Future benchmarks look at CSV to delta and PBI imports.
General Summary
In this benchmark, I generated ~2 billion rows of sales data using the Contoso data generator on a F8as_v6 virtual machine in Azure with a terabyte of premium SSD. This took about 2 hours (log) and produced 194 GB of files, which works out to about $1-2 as far as I can tell (assuming you shut down the VM and delete the premium disk quickly). You could easily do it for cheaper, since it only needed about 16 GB of RAM.
In general, I would create a separate lakehouse for each test and a separate workspace for each run of a given test. This was tedious and inefficient, but the easiest way to get clean results from the Fabric Capacity Metrics app without automation or custom reporting. I tried to set up Will Crayger’s monitoring tool but ran into some issues and will be submitting some pull requests.
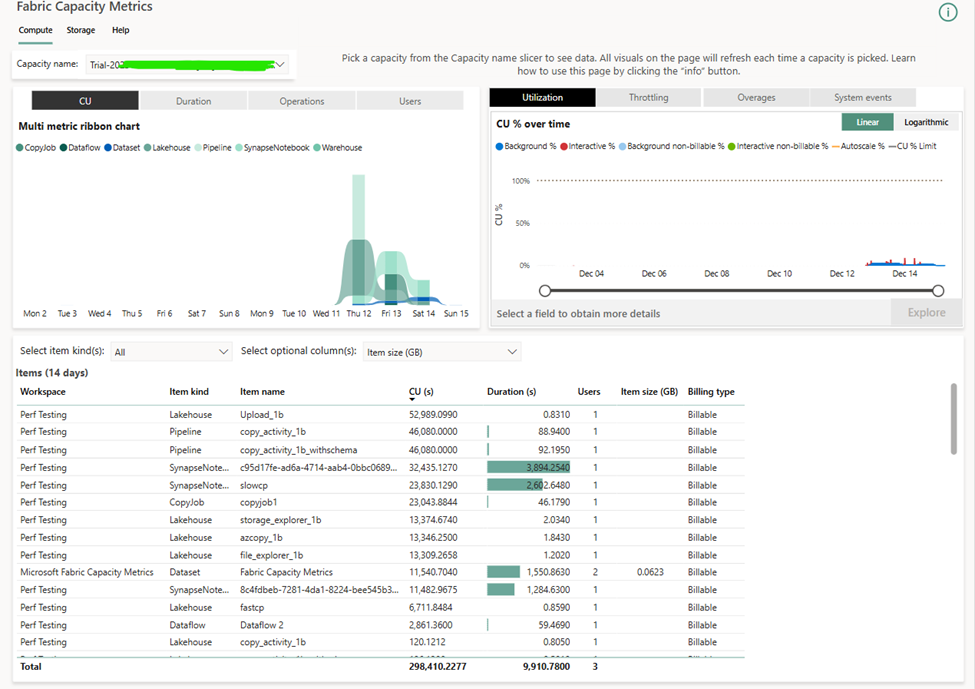
To get the CU seconds, I copied from the Power BI visual in the metrics app and tried to ignore incidental costs (like creating a SQL endpoint for a lakehouse). To get the costs, I took the price of an F2 in East US 2 ($162/mo), divided it by the number of CUs (2 CUs), and divided by the number of seconds in 30 days (30*24*60*60). This technically overestimates the costs for months with 31 days in them.
Anyway, here are the numbers:
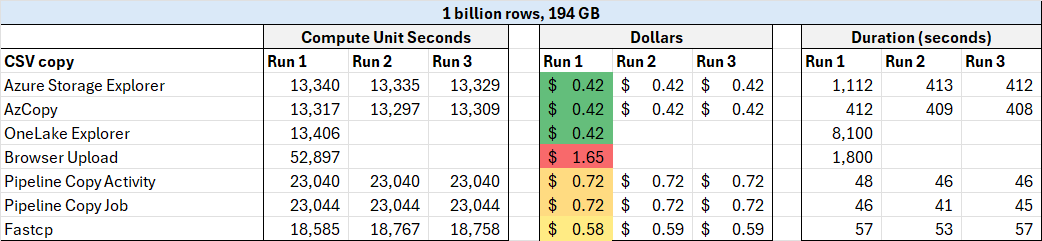
External methods of file upload (Azure Storage explorer, AZ Copy, and OneLake File Explorer) are clear winners, and browser based upload is a clear loser here. Do be aware that external methods may have external costs (i.e. Azure costs).
Data Generation process
As I mentioned, I spun up a beefy VM and ran the Contoso Data Generator, which is surprisingly well documented for a free, open source tool. You’ll need .NET 8 installed to build and run the tool. The biggest thing is that you will want to modify the config file if you want a non-standard size for your data. In my case, I wanted 1 billion rows of data (OrdersCount setting) and I limited each file to 10 million rows of data (CsvMaxOrdersPerFile setting). This technically will produce 1 billion orders so 2 actually billion sales rows when order header is combined with order lineitem. This produced 100 sales files of about 1.9 GB each.
I was hoping the temporary SSD drive included with Azure VMs was going to be enough, but it was ~30 GB if I recall, not nearly big enough. So instead, I went with Premium SSD storage instead, which has the downside of burning into my Azure Credits for as long as it exists.
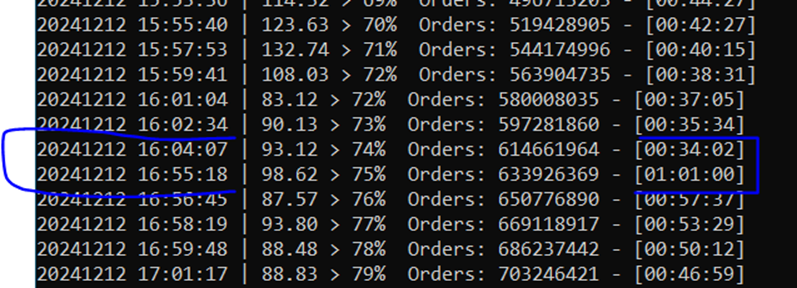
One very odd note, at around %70 percent complete, the data generation halted for no particular reason for about 45 minutes. It was only using 8 GB of the 32 GB available and was completely idle with no CPU activity. Totally bizarre. You can see it in the generation log. My best theory is it was waiting for the file system to catch up.
Lastly, I wish I was aware of how easy it was to expand the VM disk image when you allocate a terabyte of SSD. Instead, I allocated the rest of the SSD as a E drive. It was still easy to generate the data, but it added needless complication.
CSV to CSV tests
Thanks to James Serra’s recent blog post, I had a great starting point to identify all the ways to load data into Fabric. That said, I’d love it if he expanded it to full paragraphs since the difference between a copy activity and a copy job was not clear at all. Additionally, the Contoso generator docs list 3 ways to load the data, which was also a helpful starting point.
I stored the data on a container on Azure Blob storage with Hierarchical Namespaces turned on and the it said the Data Lake Storage endpoint is turned on by default, making it Azure Data Lake Storage Gen 2? At least I think it does, but I don’t know for sure and I have no idea how to tell.
Azure storage Explorer
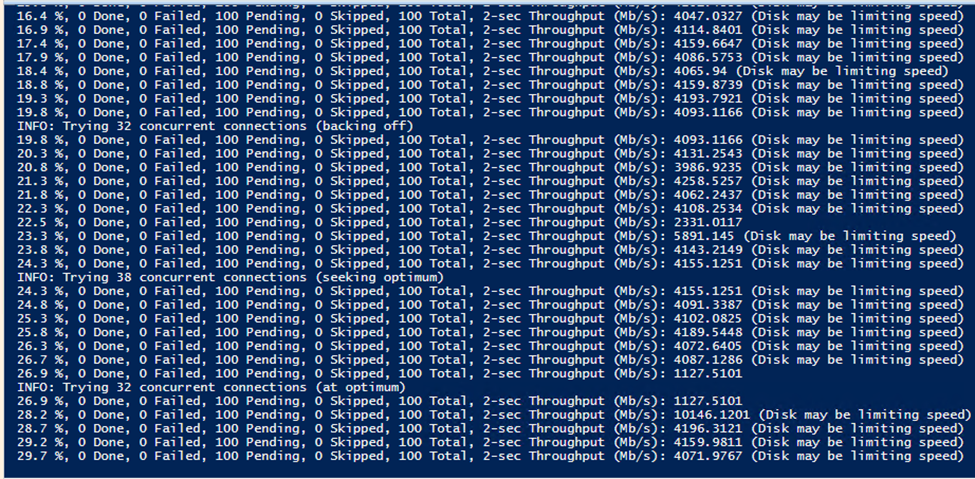
The Azure Storage Explorer is pretty neat and I was able to get it running without issue or confusion. Here are the docs for connecting to OneLake, it’s really straightforward. I did lose my RDP connection during all three of the official tests, because it maxed out IO on the disk which was the OS disk. I probably should have made a separate data disk, UGH. Bandwidth would fluctuate wildly between 2,000 and 8,000 Mbps. I suspect a separate disk would go even faster. The first time I had tested it, I swear it stayed at 5,000 Mbps and took 45 seconds, but I failed to record that.
It was also mildly surprising to find there was a deletion restriction for workspaces with capital letters in the name. Also, based on the log files in the .azcopy folder, I’m 95% sure the storage explorer is just a wrapper for AzCopy
AzCopy
AzCopy is also neat, but much more complicated, since it’s a command line program. Thankfully, Azure Storage Explorer let me export the AzCopy commands so I ran that instead of figuring it out myself or referencing the Contoso docs.
If you go this route, you’ll get a message like “To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ABCDE12FG to authenticate”. This authentication could be done from any computer, not just the VM, which was neat.
I got confirmation from the console output that the disk was impacting upload speeds. Whoops.
OneLake File Explorer
The OneLake File Explorer allows you to treat your OneLake like it was a OneDrive Folder. This was easy to set up and use, with a few minor exceptions. First, it’s not supported on Windows Server and in fact I couldn’t find a way at all to install the MISX file on Windows Server 2022. I tried to follow a guide to do that, but no luck.
The other issue is I don’t know what the heck I’m doing, so I didn’t realize I could expand the C Drive on the default image. Instead, I allocated the spare SSD space to the F drive. But when I tried to copy the files to the C drive, there wasn’t enough space, so I had them in 3 batches of 34 files.
This feature is extremely convenient but was challenging to work with at this scale. First, because it’s placed under the Users folder, both Windows search index and anti-virus were trying to scan the files. Additionally, because my files were very large, it would be quite slow when I deallocated files to free up space.
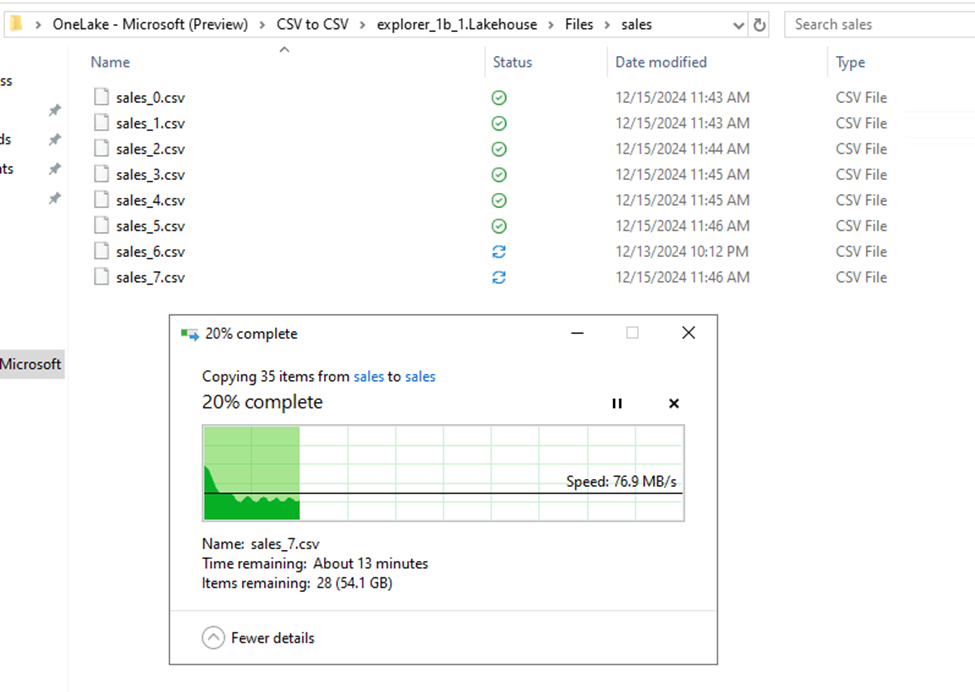
Oddly, the first batch stayed around 77 MB/s, the second was around 50 MB/s, and the last batch tanked to a speed of 12 MB/s, more than doubling the upload time. Task Manager showed disk usage at 100%, completely saturated. I tried taking a look at resource monitor but I didn’t see anything unusual. Most likely it’s just a bad idea to copy 194 GB from one drive back to itself, while deallocating the files in-between.
Browser Upload
Browser-based file upload was the most expensive in terms of CUs but was very convenient. It was shockingly stable as well. I’ve had trouble downloading multiple large files with Edge/Chrome before, so I was surprised it uploaded one hundred 2 GB files without issue or error. It took 30 minutes, but I expected a slowdown going via browser so not complaints here. Great feature.
Pipeline Copy Activity
Setting up a pipeline copy activity to read from Azure Blob storage was pretty easy to do. The biggest challenge was navigating all the options without feeling overwhelmed.
Surprisingly, there was no measurable difference in CUs between schema agnostic (binary) copy and not schema agnostic (CSV validation) copy. However, all the testing returned the same cost, so I’m guessing the costing isn’t as granular and doesn’t pick up a 2 second difference between runs.
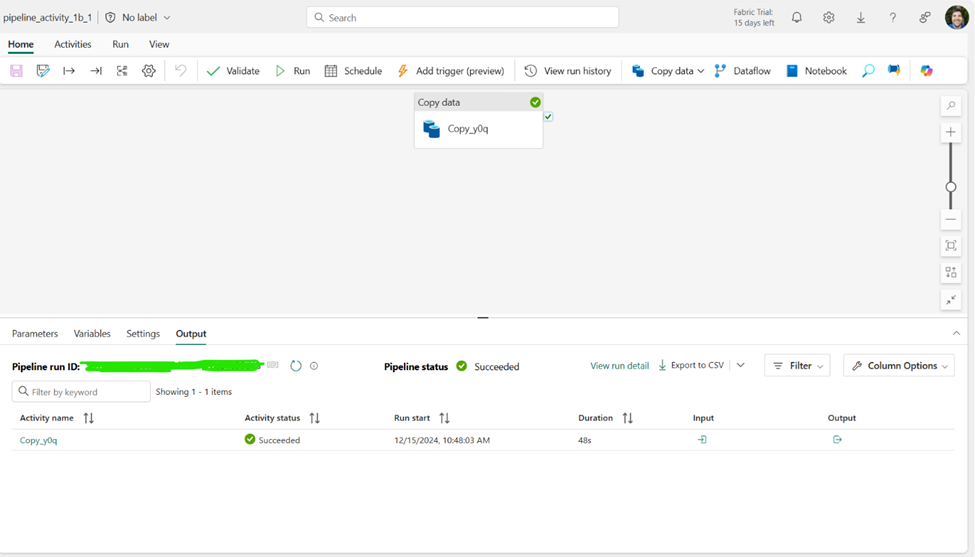
Based on the logs it looks like it may also be using AzCopy because azCopyCommand was logged as true. It’s AzCopy all the way down apparently. The CU cost (23,040) is exactly equal to 2 times the logged copy duration (45 s) times the usedDataIntegrationUnits (256), so I suspect this is how it’s costed, but I have no way of proving it. It would explain why there was no cost variation between runs.
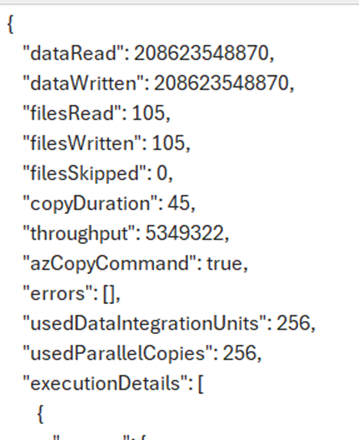
Pipeline Copy Job
The copy job feature is just lovely. I was confused based on the name how it differed from a copy activity, but it seems to be a simpler way of copying files with fewer overwhelming options and nicer UI that clearly shows throughput, etc. The JSON code also looks very simple. Just wonderful overall.
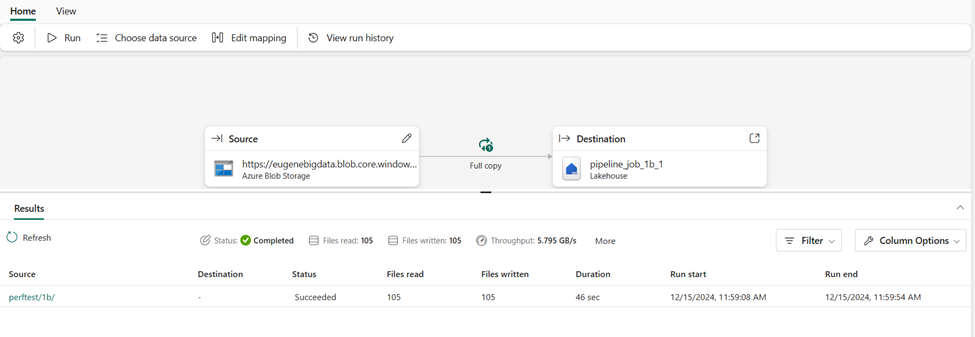
It is in preview, so you will have to turn it on. But that’s just an admin toggle. Reitse Eskens has a nice blog post on it. My only complaint is I didn’t see a way to copy a job or import the JSON code.
Spark Notebook – Fast copy
My friend Sandeep Pawar recommended trying fastcp from notbookutils in order to copy files with spark. The documentation is fairly sparse for now, but Sandeep has a short blog post that was helpful. Still, understanding the exact URL structure and how to authenticate was a challenge.
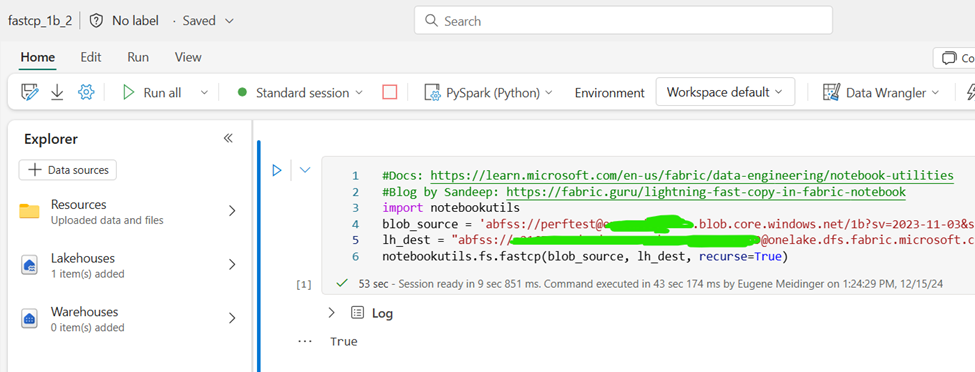
Fastcp is a wrapper for….you guessed it, AzCopy. It seems to take the same time as all the other options running AzCopy (45 seconds) + about 12 seconds for spinning up a Spark session as far as I can tell. Sandeep has told me that it also works in Python for cheaper, but when I ran the same code I got an authorization error.
Overall, I see the appeal of Spark notebooks, but one frustration was that DAX has taught me to press Alt + Enter when I need a newline, which does the exact opposite in notebooks and will instead execute a cell and make a new one.
Learnings and paper cuts
I think my biggest knowledge gap overall was in the precise difference between blob storage and ADLS storage gen 2, as well as access URLS and access methods. Multiple times I tried to generate an SAS key from the Azure Portal and got an error when I tried to use it. Once, out of frustration I copied the one from the export to AzCopy option into my spark notebook to get it to work. Another time I used the generate SAS UI in the storage explorer and that worked great.
Even trying to be aware of all the ways you can copy both CSV files as well as convert CSV to delta is quite a bit to take on. I’m not sure how anyone does it.
My biggest frustration with Fabric right now is around credentials management. Because I had made some different tests, if I searched for “blob”, 3 options might show up (1 blob storage, 2 ADLS).
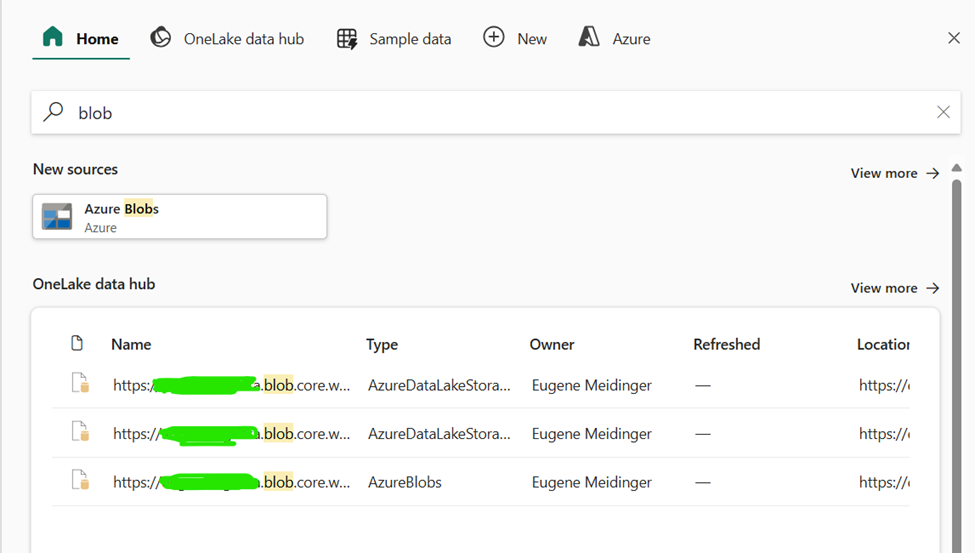
Twice, I clicked on the wrong one (ADLS) and got an error. The icons and name are identical so the only way you can tell the difference is by “type”.
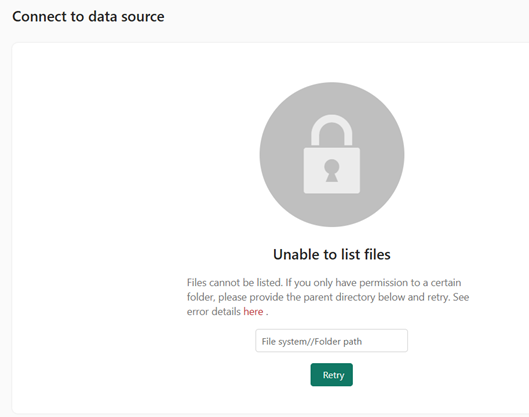
This is just so, so frustrating. Coming from Power BI, I know exactly where the data connection is because it’s embedded in the semantic model. In OneLake it appears that connections are shared and I have no idea what scope they are shared within (per user, per workspace, per domain?) and I have no idea where to go to mange them. This produces a sense of unease and being lost. It also led to frustration multiple times when I tried to add a lakehouse data source but my dataflow already had that source.
What I would love to see from the team is some sort of clear and easily accessible edit link when it pulls in an existing data source. This would be simple (I hope) and would lead to a sense of orientation, the same way that the settings section for a semantic model has similar links.
Leave a Reply