The more I tried to research practical ways to make use of ChatGPT and Power BI, the more pissed I became. Like bitcoin and NFTs before it, this is a world inextricably filled with liars, frauds, and scam artists. Honestly many of those people just frantically erased blockchain from their business cards and scribbled on “AI”.
There are many valid and practical uses of AI, I use it daily. But there are just as many people who want to take advantage of you. It is essential to educate yourself on how LLMs work and what their limitations are.
Other than Kurt Buhler and Chris Webb, I have yet to find anyone else publicly and critically discussing the limitations, consequences, and ethics of applying this new technology to my favorite reporting tool. Aside from some video courses on LinkedIn Learning, nearly every resource I find seems to either have a financial incentive to downplay the issues and limitations of AI or seems to be recklessly trying to ride the AI hype wave for clout.
Everyone involved here is hugely biased, including myself. So, let’s talk about it.
Legal disclaimer
Everything below is my own personal opinion based on disclosed facts. I do not have, nor am I implying having, any secret knowledge about any parties involved. This is not intended as defamation of any individuals or corporations. This is not intended as an attack or a dogpile on any individuals or corporations and to that effect, in all of my examples I have avoided directly naming or linking to the examples.
Please be kind to others. This is about a broader issue, not about any one individual. Please do not call out, harass, or try to cancel any individuals referenced in this blog post. My goal here is not to “cancel” anyone but to encourage better behavior through discussion. Thank you.
LLMs are fruit of the poisoned tree
Copyright law is a societal construct, but I am a fan of it because it allows me to make a living. I’m not a fan of it extending 70 years after the author’s death. I’m not a fan of companies suing against archival organizations. But If copyright law did not exist I would not have a job as a course creator. I would not be able to make the living I do.
While I get annoyed when people pirate my content, on some level I get it. I was a poor college student once. I’ve heard the arguments of “well they wouldn’t have bought it anyway”. I’ll be annoyed about the $2 I missed out on, but I’ll be okay. Now, if you spin up a BitTorrent tracker and encourage others to pirate, I’m going to be furious because you are now directly attacking my livelihood. Now it is personal.
Whatever your opinions are on the validity of copyright law and whether LLMs count as Fair Use or Transformative Use, one thing is clear. LLMs can only exist thanks to massive and blatant copyright infringement. LLMs are fruit of the poisoned tree. And no matter how sweet that fruit, we need to acknowledge this.
Anything that is publicly available online is treated as fair game, regardless of whether or not the author of the material has given or even implied permission, including 7,000 Indie books that were priced at $0. Many lawsuits allege that non-public, copywritten material is being used, given AI’s ability to reproduce snippets of text verbatim. In an interview with the Wall Street Journal, Open AI’s CTO dodged the question on whether SORA was trained on YouTube videos.
Moving forward, I will be pay-walling more and more of my content as the only way to opt-out of this. As a consequence, this means less free training material for you, dear reader. There are negative, personal consequences for you.
Again, whatever your stance on this is (and there is room for disagreement on the legalities, ethics, and societal benefits), it’s shocking and disgusting that this is somehow all okay, but in the early 2,000s the RIAA and MPAA sued thousands of individuals for file-sharing and copyright infringement, including a 12 year old girl. As a society, there is a real incoherence around copyright infringement that seems to be motivated primarily by profit and power.
The horse has left the barn
No matter how mad or frustrated I may get, the horse has permanantly left the barn. No amount of me stomping my feet will change that. No amount of national regulation will change that. You can run a GPT-4 level LLM on a personal machine today. Chinese organizations are catching up in the LLM race. And I doubt any Chinese organization intends on listening to US or EU regulations on the matter.
Additionally, LLMs are massively popular. One survey in May 2024 (n=4010) of participants in the education system found that 50% of students and educators were using ChatGPT weekly.
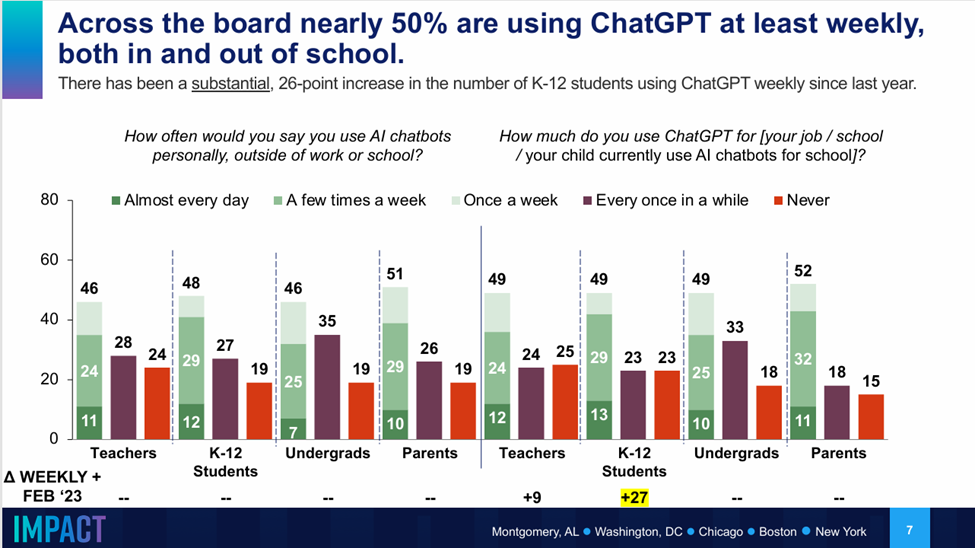
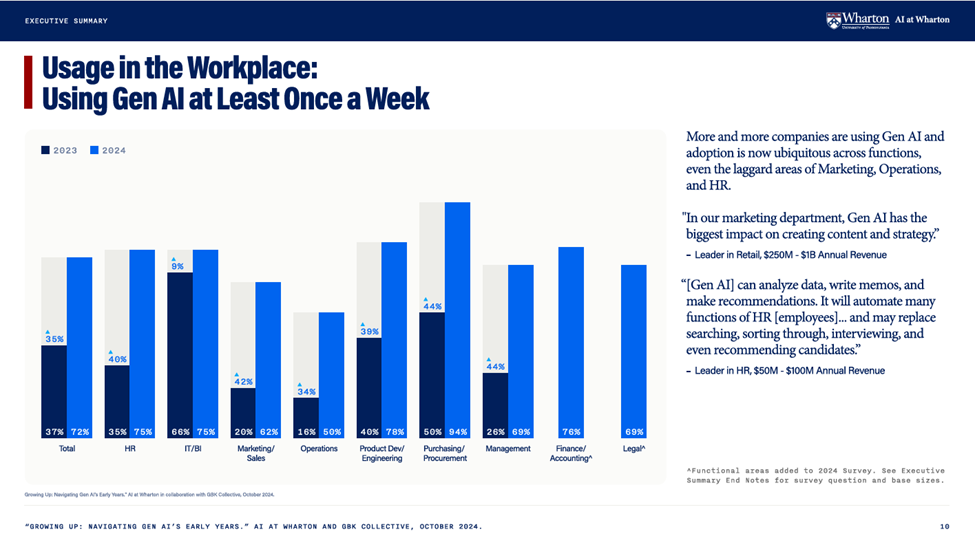
Another survey from the Wharton Business School of 800 business leaders found that weekly usage of AI had from up from 37% in 2023 to 73% in 2024.
Yet another study found that 24% of US workers aged 18-64 use AI on a weekly basis.

If you think that AI is a problem for society, then I regret to inform you that we irrevocably screwed. The individual benefits and corporate benefits are just too strong and enticing to roll back the clock on this one. Although I do hope for some sort of regulation in this space.
So now what?
While we can vote for and hope for regulation around this, no amount of regulation can completely stop it, in the same way that copyright law has utterly failed to stop pirating and copyright infringement.
Instead, I think the best we can do it to try to hold ourselves and others to a higher ethical standard, no matter how convenient it may be to do otherwise. Below are my opinions on the ethical obligations we have around AI. Many will disagree, and that’s OK! I don’t expect to persuade many of you, in the same way that I’ll never persuade many of my friends to not pirate video games that are still easily available for sale.
Obligations for individuals
As an individual, I encourage you to educate yourself on how LLMs work and their limitations. LLMs are a dangerous tool and you have an obligation to use them wisely.
Here are some of my favorite free resources:
- Intro to Large Language Models – Andrej Karpathy
- Large Language Models explained Briefly – Grant Sanderson
- Transformers (how LLMs work) explained visually – Grant Sanderson
- Let’s Build GPT: from scratch, in code, spelled out – Andrej Karpathy
- What is ChatGPT Doing and Why Does it Work? – Stephen Wolfram
- One Useful Thing – Ethan Mollick
Additionally, Co-Intelligence Living and Working with AI by Ethan Mollick is a splendid, splendid book on the practical use and ethics of LLMs and can be gotten cheaply at Audible.
If you are using ChatGPT for work, you have an obligation to understand when and how it can train on your chat data (which is does by default). You have an ethical obligation to follow your company’s security and AI policies to avoid accidentally exfiltrating confidential information.
I also strongly encourage you to ask ChatGPT questions in your core area of expertise. This is the best way to understand the jagged frontier of AI capabilities.
Obligations for content creators
If you are a content creator, you have an ethical obligation to not use ChatGPT as a ghostwriter. I think using it for a first pass can be okay and using it for brainstorming or editing is perfectly reasonable. Hold yourself to the same standards to as if you were using a human.
For example, if you are writing a conference abstract and you use ChatGPT, that’s fine. I have a friend who I help edit and refine his abstracts. Although, be aware that if you don’t edit the output, the organizers can tell because it’s going to be mediocre.
But if you paid someone to write an entire technical article and then slapped your name on it, that would be unethical and dishonest. If I found out you were doing that, I would stop reading your blog posts and in private I would encourage others to do the same.
You have an ethical obligation to take responsibility for the content you create and publish. To not do so is functionally littering at best, and actively harmful and malicious at worst. To publish an article about using Power BI for DAX without testing it first is harmful and insulting. Below is an article on LinkedIn with faulty DAX code that subverted the point of the article. Anyone who tried to use the code would have potentially wasted hours troubleshooting.
Don’t put bad code online. Don’t put untested code online. Just don’t.

One company in the Power BI space has decided to AI generate articles en masse, with (as far as I can tell), no human review for quality. The one on churn rate analysis is #2 on the search results for Bing.

When you open the page, it’s a bunch of AI generated slop including the ugliest imitation of the Azure Portal I have ever seen. This kind of content is a waste of time and actively harmful.
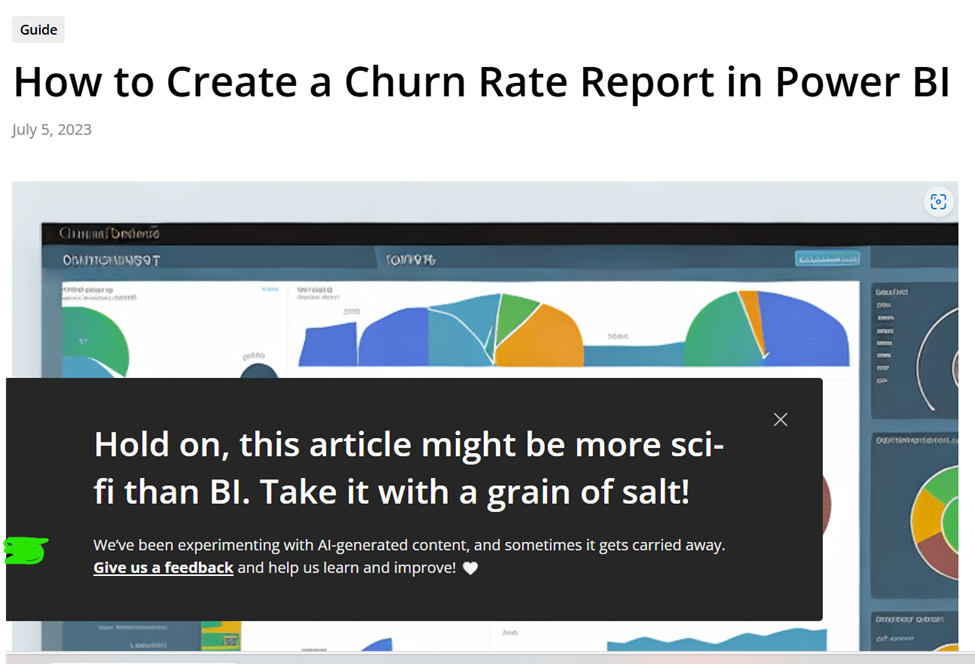
I will give them credit for at least including a clear disclaimer, so I don’t waste my time. Many people don’t do even that little. Unfortunately, this only shows up when you scroll to the bottom. This means this article wasted 5-10 minutes of my time when I was trying to answer a question on Reddit.
Even more insultingly, they ask for feedback if something is incorrect. So, you are telling me you have decided to mass litter content on the internet, wasting people’s time with inaccurate posts and you want me to do free labor to clean up your mess and benefit your company’s bottom line? No. Just no.
Now you may argue “Well, Google and Bing do it with their AI generated snippets. Hundreds of companies are doing it.”. This is the most insulting and condescending excuse I have ever heard. If you are telling me that your ethical bar is set by what trillion dollar corporations are doing, well then perhaps you shouldn’t have customers.
Next, If you endorse an AI product in any capacity, you have an ethical obligation to announce any financial relationship or compensation you receive from that product. I suspect it’s rare for people in our space to properly disclose these financial relationships, and I can understand why. I’ve been on the fence on how much to disclose in my business dealings. However, I think it’s important and I make an effort to do it for any company that I’ve done paid work with, as that introduces a bias into my endorsement.
These tools can produce bad or even harmful code. These tools are extremely good at appearing to be more capable than they actually are. It is easily to violate the data security boundary with these tools and allow them to train their models on confidential data.
For goodness sake, perhaps hold yourself to a higher ethical standard than an influencer on TikTok.
Obligations for companies
Software companies that combine Power BI and AI have an obligation to have crystal clear documentation on how they handle both user privacy and data security. I’m talking architecture diagrams and precise detail about what if any user data touches your servers. A small paragraph is woefully inadequate and encourages bad security practices. Additionally, this privacy and security information should be easily discoverable.
I was able to find three companies selling AI visuals for Power BI. Below is the entirely of the security statements I could find, outside of legalese buried in their terms of service or privacy documents.
While the security details are hinted at in the excerpts below, I’m not a fan of “just trust us, bro”. Any product that is exfiltrating your data beyond the security perimeter needs to be abundantly clear on the exact software architecture and processes used. This includes when and how much data is sent over the wire. Personally, I find the lack of this information to be disappointing.
Product #1
“[Product name] provides a secure connection between LLMs and your data, granting you the freedom to select your desired configuration.”
“Why trust us?
Your data remains your own. We’re committed to upholding the highest standards of data security and privacy, ensuring you maintain full control over your data at all times. With [product name], you can trust that your data is safe and secure.”
“Secure
At [Product name], we value your data privacy. We neither store, log, sell, nor monitor your data.
You Are In Control
We leverage OpenAI’s API in alignment with their recommended security measures. As stated on March 1, 2023, “OpenAI will not use data submitted by customers via our API to train or improve our models.”
Data Logging
[Product name] holds your privacy in the highest regard. We neither log nor store any information. Post each AI Lens session, all memory resides locally within Power BI.”
Product #2
Editors Note: this sentence on appsource was the only mention of security I could find. I found nothing on the product page.
“This functionality is especially valuable when you aim to offer your business users a secure and cost-effective way of interacting with LLMs such as ChatGPT, eliminating the requirement for additional frontend hosting.”
Product #3
“ Security
The data is processed locally in the Power BI report. By default, messages are not stored. We use the OpenAI model API which follows a policy of not training their model with the data it processes.”
“Is it secure? Are all my data sent to OpenAI or Anthropic?
The security and privacy of your data are our top priorities. By default, none of your messages are stored. Your data is processed locally within your Power BI report, ensuring a high level of confidentiality. Interacting with the OpenAI or Anthropic model is designed to be aware only of the schema of your data and the outcomes of queries, enabling it to craft responses to your questions without compromising your information. It’s important to note that the OpenAI and Anthropic API strictly follows a policy of not training its model with any processed data. In essence, both on our end and with the OpenAI or Anthropic API, your data is safeguarded, providing you with a secure and trustworthy experience.”
Clarity about the model being used
Software companies have an obligation to clearly disclose which AI model they are using. There is a huge, huge difference in quality between GPT 3.5, GPT 4o mini, and GPT 4o. Enough so that to not be clear on this is defrauding your customers. Thankfully, some software companies are good about doing this, but not all.
Mention of limitations
Ideally, any company selling you on using AI will at least have some sort of reasonable disclaimer about the limitations of AI and for Power BI, which things AI is not the best at. However, I understand that sales is sales and that I’m not going to win this argument. Still, this frustrates me.
Final thoughts
Thank you all for bearing with me. This was something I really needed to get off my chest.
I don’t plan on stopping using LLMs anytime soon. I use ChatGPT daily in my work and I recently signed up for GitHub Copilot and plan to experiment with that. If I can ever afford access to an F64 SKU, I plan to experiment with Copilot for Fabric and Power BI as well.
If you are concerned about data security, I recommend looking into tools like LM studio and Ollama to safely and securely experiment with local LLMs.
I think if used wisely and cautiously, these can be an amazing tool. We all have an obligation to educate ourselves on the best use of them and their failings. Content creators have an obligation to disclose financial incentives, when they use ChatGPT heavily to create content, and general LLM limitations. Software companies have an obligation to be crystal clear about security and privacy, as well as which models they use.
