If you are a small (or even medium) business, you may be wondering “What is Fabric and do we even need it?” If you are primarily on Power BI Pro licenses today, you may not find a compelling reason to switch to Fabric today, but the value add should improve over time as new features are added on the Fabric side and some features get deprecated on the Power BI side.
If you have the budget, time, and luxury, then you should start playing around with a Fabric 60-day trial today and continue to experiment with a pausible F2 afterwards. Not because of any immediate value add, but because when the time comes to consider using Fabric, it will be far less frustrating to evaluate your use cases.
This will cost $0.36 per hour for pausible capacity (plus storage). Roughly $270/mo if you left it on all the time. See here for a licensing explanation in plain English. Folks on Reddit have shared when they found the entry level F2 to be useful.
Warning! Fabric provides for bursting and smoothing, with up to 32x consumption for an F2. This means that if you run a heavy workload and immediately turn off your F2, you may get billed as if you had run an F64 because smoothing isn’t given time to pay back down the CU debt. If you are using an F2, you 100% need to research surge protection (currently in preview).
Microsoft is providing you with an ever growing buffet of tools and options withing Fabric, but also like a buffet if someone had food allergies or dietary restrictions, it would be reckless to toss them at it and say “Good luck!”.
What the Fabric is Microsoft Fabric?
If you are a Power BI user, Microsoft Fabric is best seen as an expansive extension of Power BI premium (and a replacement) in order to compete in the massively parallel processing space, similar to tools like Databricks and Snowflake. Fabric does have mirroring solutions for both of those products, so it doesn’t have to be a strict replacement.
Microsoft has not had success in this space historically and has decided to take a bundled approach with Power BI. This bundling means that over time, there will be more motivation for Power BI users to investigate Fabric as a tool as the value of Fabric increases.
Fabric is an attempt to take a Software-as-a service approach to the broader Azure data ecosystem, strongly inspired by the success of Power BI. However, this can lead to frustration as you are given options and comparisons, but not necessarily explicit guidance.
Metaphorically speaking, Microsoft is handing you a salad fork and a grapefruit spoon, but no one is telling you “You are eating a grapefruit, use the grapefruit spoon!” This blog post attempts to remedy that with explicit instructions and personal opinions.
The core of Fabric is heavily inspired by the Databricks lakehouse approach specifically, and data lakes more generally. In short, data lakes make sense when it’s cheaper to store the data rather than figure out what to keep. A data lakehouse is the result of taking a lake-first approach and then figuring out how to recreate the flexibility, consistency, and convenience of a SQL endpoint.
How should you approach fabric?
If you are comfortable with Microsoft Power BI, you should give preference to tools that are built on the same technology as Power BI. This means Gen2 dataflows (which are not a feature superset of Gen 1 dataflows), visual SQL queries, and your standard Power BI semantic models. You should only worry about data pipelines and Spark notebooks if and when you run into performance issues with dataflows, which are typically more expensive to run. See episode 1 of the Figuring out Fabric podcast for more on when to make the switch.
In terms of data storage, if you are happily pulling data from your existing data sources such as SQL Server or Excel, there is no urgent reason to switch to a lakehouse or a data warehouse as your data source. These tools provide better analytical performance (because of column compression) and a SQL endpoint, but if you are only using Power BI import mode, these features aren’t huge motivators. The Vertipaq engine already provides column compression.
In terms of choosing a Lakehouse versus a Warehouse, my recommendation is use a Lakehouse for experimentation or as a default and a Warehouse for standalone production solutions. More documentation, design patterns, and non-MSFT content exist around lakehouses. Fabric Data Warehouses are more of a Fabric-specific offshoot.
Both are backed by OneLake Storage, which is really Azure Data lake storage, which is really Azure Blob storage but with folder support and big data APIs. Both use the Parquet file format, which is column compressed similar to the Vertipaq engine in Power BI. Both use Delta lake to provide transactional guarantees for adds and deletes.
Important: I have covered delta lake and a lot of the motivation to use these tools in this user group presentation.
Lakehouses are powered by the Spark engine, are more flexible, more interoperable, and more popular than Fabric-style data warehouses. Fabric Data Warehouses are not warehouses in the traditional sense. Instead, they are more akin to modern lakehouses but with stronger transactional guarantees and the ability to write back to the data source via T-SQL. That is to say that a Fabric Data warehouse is closer in lineage to Hadoop or Databricks than it is to SQL Server Analysis services or a Star Schema database on SQL Server.
What are the benefits of Fabric?
In the same way that many of the benefits of Power Query don’t apply to people with clean data living in SQL databases, many of the benefits of Fabric may not apply to you, such as Direct Lake (which in my opinion is most useful with more than 100 million rows). Fabric, in theory, provides a single repository of data for data scientists, data engineers, BI developers, and business users to work together. But.
If you are a small business, you do not have any data scientists or data engineers. In fact, your BI dev is likely your sole IT person or a savvy business user who has been field promoted into Power BI dev.
If Power BI is the faucet of your data plumbing, the benefits of industrial plumbing are of little benefit or interest to you. However, you may be interested in setting up or managing a cistern or well, metaphorically speaking. Or you may want to move from a well and an outhouse to indoor plumbing. This is where Fabric can be of value to you.
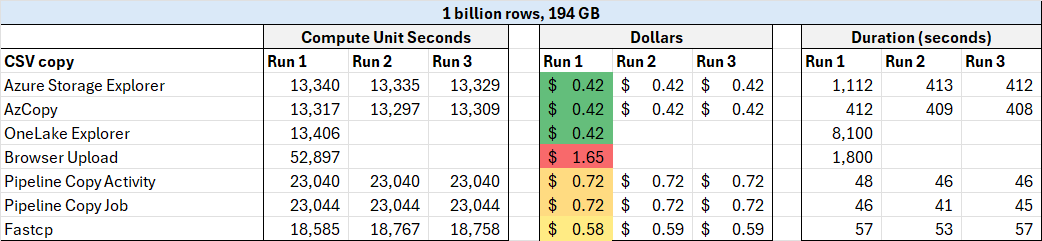
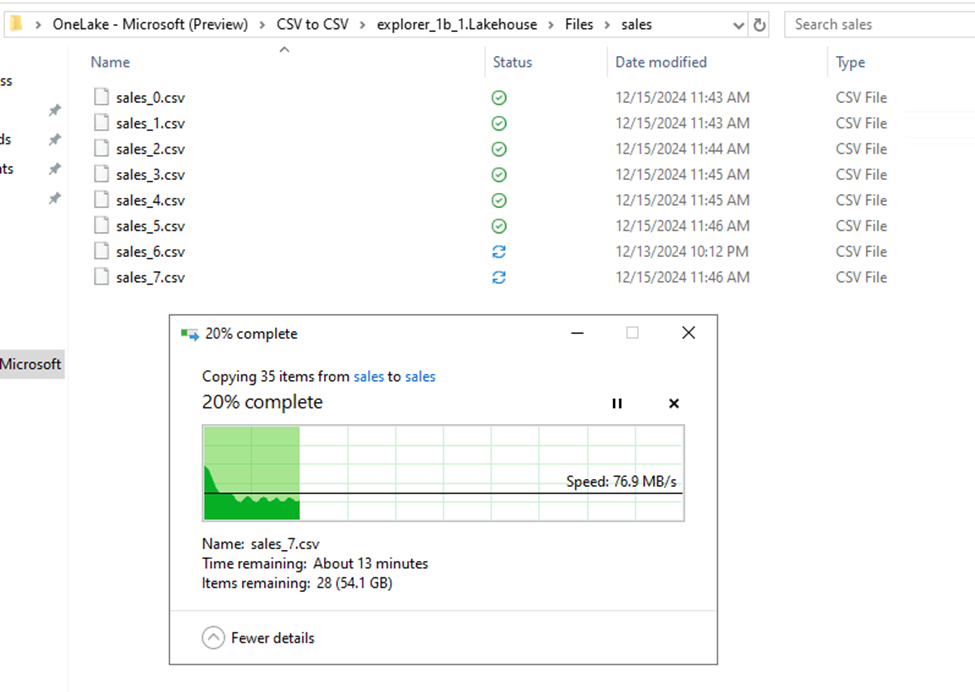
There are three main benefits of Fabric to small business users, in my opinion. First is if you have a meaningful amount of data in flat files such as Excel and CSV. In my testing, Parquet loads 59% faster and the files are 78% smaller. Compression will vary wildly based on the shape of the data but will follow very similar patterns as the Vertipaq engine in Power BI. Also technically speaking, in Fabric you are not reading directly from the raw Parquet files into Power BI. Instead, you are going though the lakehouse with Direct Lake or the SQL Analytics Endpoint.
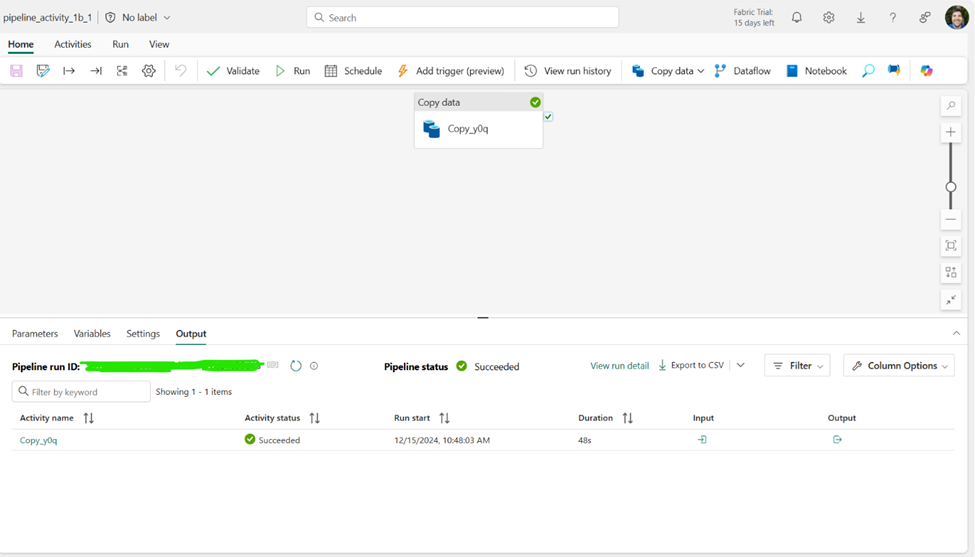
Moving that data into a Lakehouse and then loading it into delta tables will likely provide a better use experience, faster Power BI refreshes, and the ability to query the data with a SQL analytics endpoint. Now, as you are already aware, flat file data tends to be ugly. This means that you will likely need to use gen 2 data flows to clean and load the data into delta tables instead of doing a raw load.
You may have heard of medallion architecture. This is more naming convention than architecture, but the idea of “zones” of increasing data quality is real and valuable. In your case, I recommend considering the files section of a lakehouse as your bronze layer, the cleaned delta tables as your silver layer and your Power BI semantic model as your gold layer. Anything more than this is overcomplicating things for a small business starting out.
The second benefit of Fabric is the ability to provide a SQL endpoint for your data. SQL is the most common and popular data querying tool available. After Excel, it is the most popular business intelligence tool in the world. This is a very similar use case to Power BI Datamarts, which after 2 years in preview are unlikely to ever leave public preview.
Last is the ability to capture and store data from APIs as well as storing a history of the data over time. This would be tedious to do in pure Power BI but is incredibly simple with gen2 data flows and a lakehouse.
What are the downsides of Microsoft Fabric?
Given that Microsoft Fabric is following a similar iterative design approach to Power BI, it is still a bit rough around the edges, in the same way that Power BI was rough around the edges for the first 3 years. Fabric was very buggy on launch and has improved a lot since then, but many items are still in public preview.
Experiment with Fabric now, so that when you feel it is ready for prime time, you are ready as well. Niche, low usage features like streaming datasets will likely be deprecated and moved to fabric. In that instance, users only had 2 weeks of notice before the ability to create new streaming datasets was removed, which is utterly unacceptable, in my humble opinion [Edit: Shannon makes a fair point in the comments that deprecation of existing solutions is fairly slow]. New features, like devops pipelines will be Fabric first and will likely not ever be backported to Power BI pro (I assume). Over time, the weight of the feature set difference will become significant.
Fabric adds a layer of complexity and confusion that is frustrating. While my hope is that Fabric is Power BI-ifying Azure, many worry that the opposite is happening instead. There are 5x the number of Fabric items you can create compared to Power BI and it is overwhelming at first. We know from Reza and Arun that more is on the way. Stick to what you know and ignore the rest.
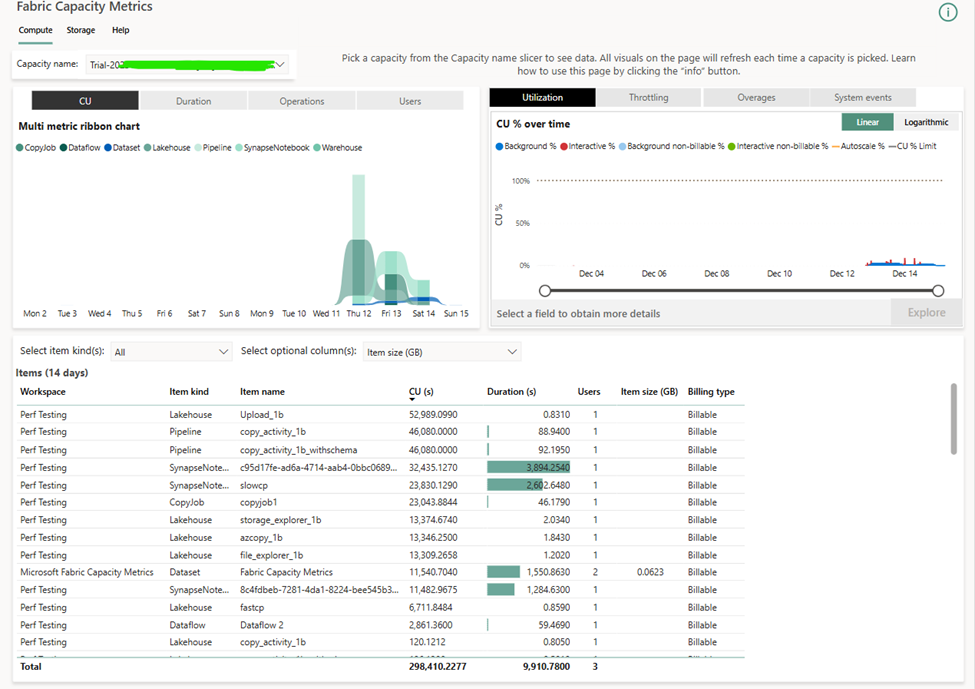
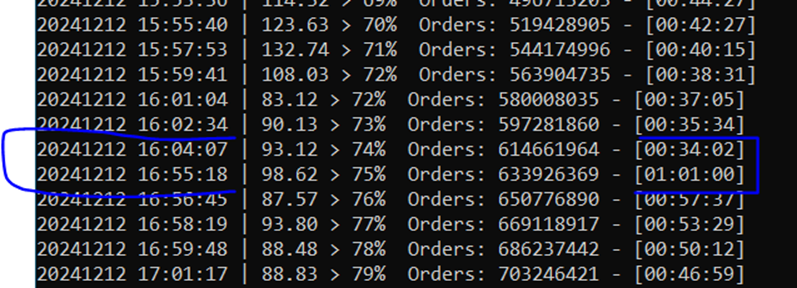
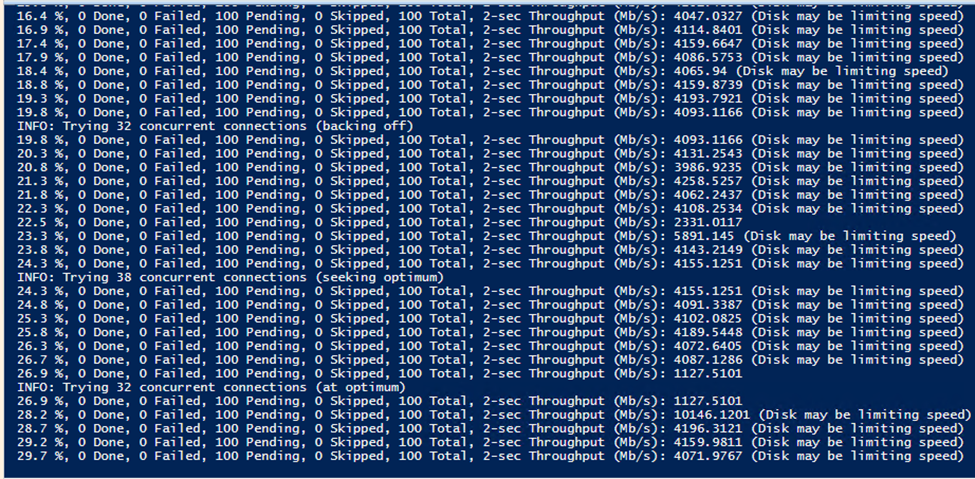
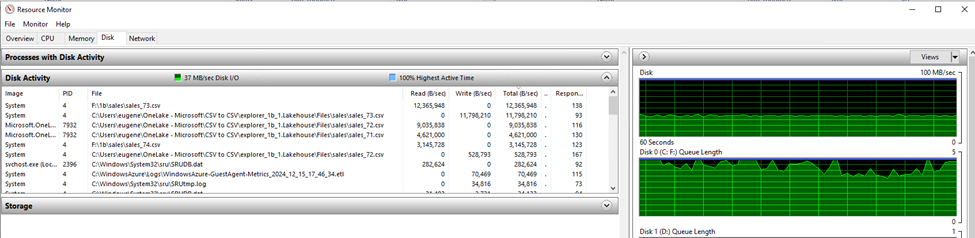
One area where this strategy is difficult is in cost management. If you plan to use Fabric, then you need to become intimately aware of the capacity management app. Because of the huge variety in workloads, there is a huge variety in cost of these workloads. When I benchmarked ways to load CSV files into Fabric, there was a 4x difference in cost between the cheapest and most expensive ways to load the data. This is not easy to predict or intuit in advance. Surge protection is currently in public preview and is desperately needed.
Another downside is that although you are charged separately for storage and compute, they are not separate from a user perspective. If you turn off or pause your Fabric capacity, you will temporarily lose access to the underlying data. From what I’ve been told, this is not the norm when it comes to lakehouses and can be a point of frustration for anyone wanting to use Fabric in an on-demand or almost serverless kind of way. In fact, Databricks offers a serverless option, something which we had in Azure Synapse but is fundamentally incompatible with the Fabric capacity model.
Sidenote: if you want to save money, you can in theory automate turning Fabric on and off for a few hours per day primarily to import data into Power BI. This is a janky but valid approach and requires a certain amount of sophistication in terms of automation and skill. You are, in a sense, building your own semi-serverless approach.
Another downside of Fabric is that you are left to your own devices when it comes to management and governance. While some tools are provided such as semantic link, you will likely have to build your own solutions from scratch with Python and Spark notebooks. Michael Kolvosky has created semantic link labs and provides a number of templates. Over time, the number of community solutions will expand.
My recommendation is to experiment with Python and Spark notebooks now so that when the time comes that you need to use them for management and orchestration, you aren’t feeling overwhelmed and frustrated. They are a popular tool for this purpose when it comes to Fabric.
Summary
So, should you use Fabric as a small business? In most cases no, in some cases yes. Should you start learning Fabric now? 100% yes. Integration between Power BI and Fabric will continue and most new features that aren’t core to Power BI (Power Query, DAX, core visuals) will show up in Fabric first.
I’ve seen multiple public calls for a Fabric Per User license. When my friend Alex Powers has surveyed people on what they would pay for an FPU license, people’s responses ranged between $30-70 per user per month. The time between Power BI Premium and PPU was 4 years and the time from Paginated Reports in Premium to Paginated Reports in Pro was 3 years. I have no insider knowledge about an FPU license, but these general ranges seem reasonable to me as estimates.
Finally, Power BI took about 4 years (2015-2019) before it felt well-polished (in my opinion) and I felt comfortable unconditionally endorsing it. I don’t think it’s unreasonable that Fabric follows a similar timeline, but that’s pure speculation on my part. I’ve started the Figuring out Fabric podcast to talk about the good and the bad, and I hope you’ll give it a listen.