For years, I told people to avoid iterators. I compared them to cursors in SQL, which are really bad, or for loops in C# which are normally fine. I knew that DAX was column based and that it often broke down when doing row-based operations, but I couldn’t tell you why.
Advice to avoid iterators is often based on a misunderstanding and a misapprehension of how the Vertipaq engine works. If you are blindly giving this advice out, like I was, you are promoting a fundamental misunderstanding of how DAX works. We think that they are running row-by-agonizing-row (RBAR). Toiling away and wasting CPU.
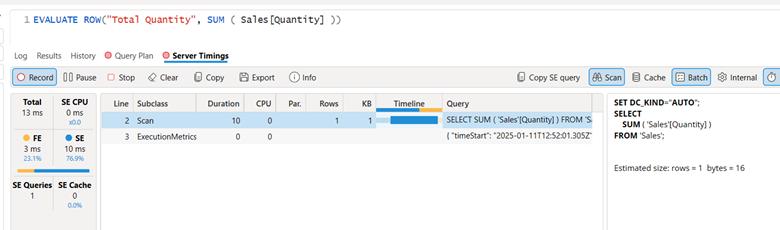
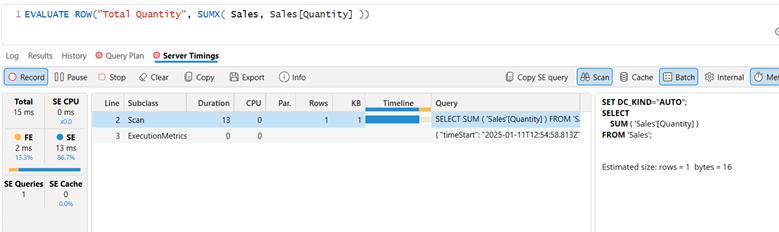
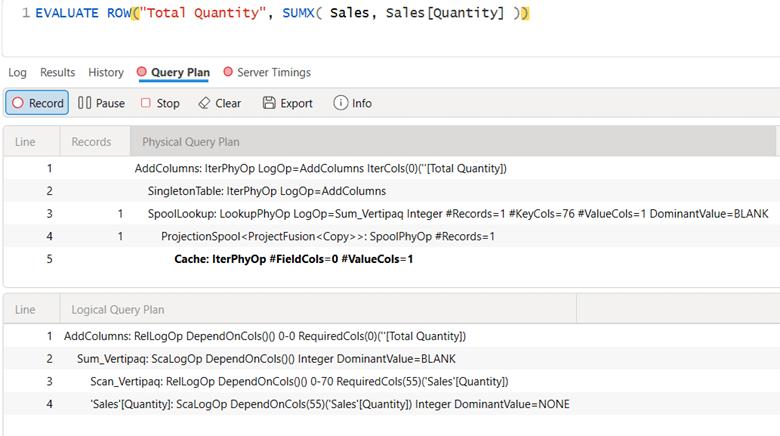
The truth is that SUM and SUMX are the same. Specifically, SUM is syntactic sugarfor SUMX. That means when you write SUM, the engine functionally rewrites it as a SUMX. There is no performance difference. There is no execution difference. There are identical execution plans. You can look for yourself.
Looking at the data
Here is the evaluation of SUM over 100 million rows of Contoso generated data, gathered with DAX Studio. With caching off, it takes 13 milliseconds and performs a single scan operation.
Here is SUMX over the same data. 15 ms, same scan operation, same xm_SQL output on the right. Any DAX within 4ms should be considered to have functionally identical performance, according to SQLBI.
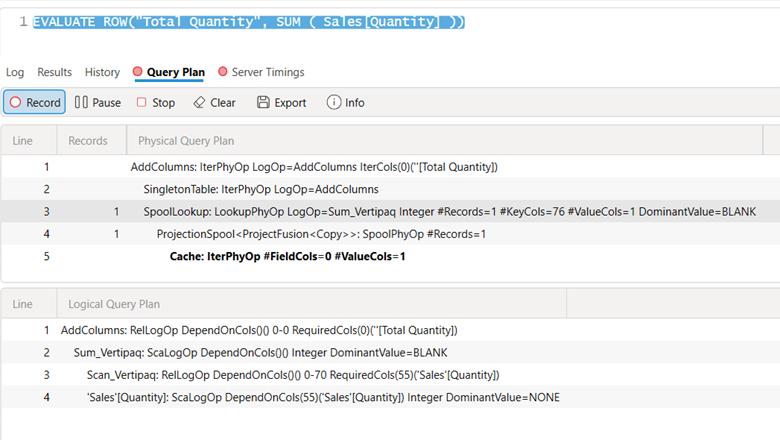
Here are the physical and logical execution plans for SUM:
Here are the logical and physical plans for SUMX. Identical.
Why the confusion?
So why is this a point of confusion? It is good to avoid row-based operations in general, but the engine often optimizes those away behind the scenes. So a blanket ban on SUM is silly and misguided.
The fact of the matter is that if you stick to functions like SUM then you will fall into the pit of success. You will have better performance, on average, because the code you write will better align with how the formula engine and the storage engine work. CALCULATE + SUM is like having a safety on your code and when you have to step outside of that and use iterators like SUMX or FILTER you know that you have to be more cautious.
Sticking to SUM will force you to engage in patterns that often lead to better performance. But SUM by itself makes no difference.
But beyond that, it’s easy to write really, really bad code with iterators. If you put an IF statement inside of your SUMX then you will see CALLBACKDATAID, which is a sign the storage engine is having to make calls to the formula engine to handle logic it can’t handle by itself. Depending on how poorly you write your SUMX, it may do the vast majority of the work in the formula engine instead of using the storage engine and sending back data caches.
First, a disclaimer: I am not a data engineer, and I have never worked with Fabric in a professional capacity. With the announcement of Fabric SQL DBs, there’s been some discussion on whether they are better for Power BI import than Lakehouses. I was hoping to do some tests, but along the way I ended up on an extensive Yak Shaving expedition.
I have likely done some of these tests inefficiently. I have posted as much detail and source code as I can and if there is a better way for any of these, I’m happy to redo the tests and update the results.
Part one focuses on loading CSV files to the files portion of a lakehouse. Future benchmarks look at CSV to delta and PBI imports.
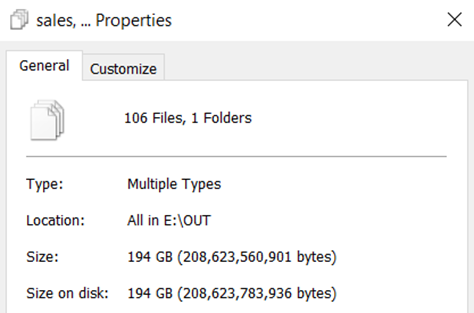
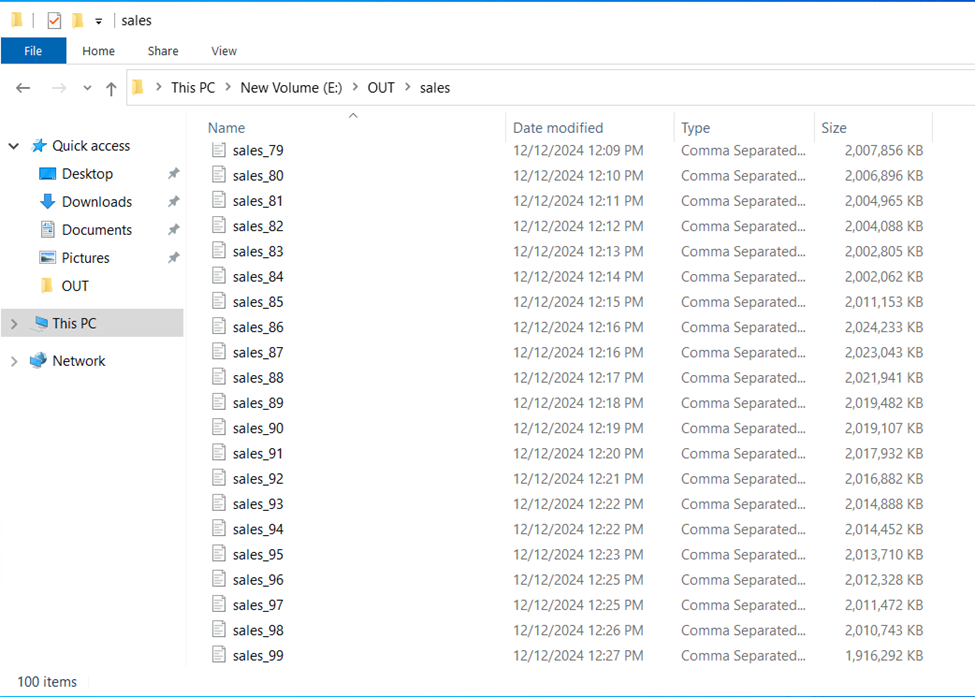
In this benchmark, I generated ~2 billion rows of sales data using the Contoso data generator on a F8as_v6 virtual machine in Azure with a terabyte of premium SSD. This took about 2 hours (log) and produced 194 GB of files, which works out to about $1-2 as far as I can tell (assuming you shut down the VM and delete the premium disk quickly). You could easily do it for cheaper, since it only needed about 16 GB of RAM.
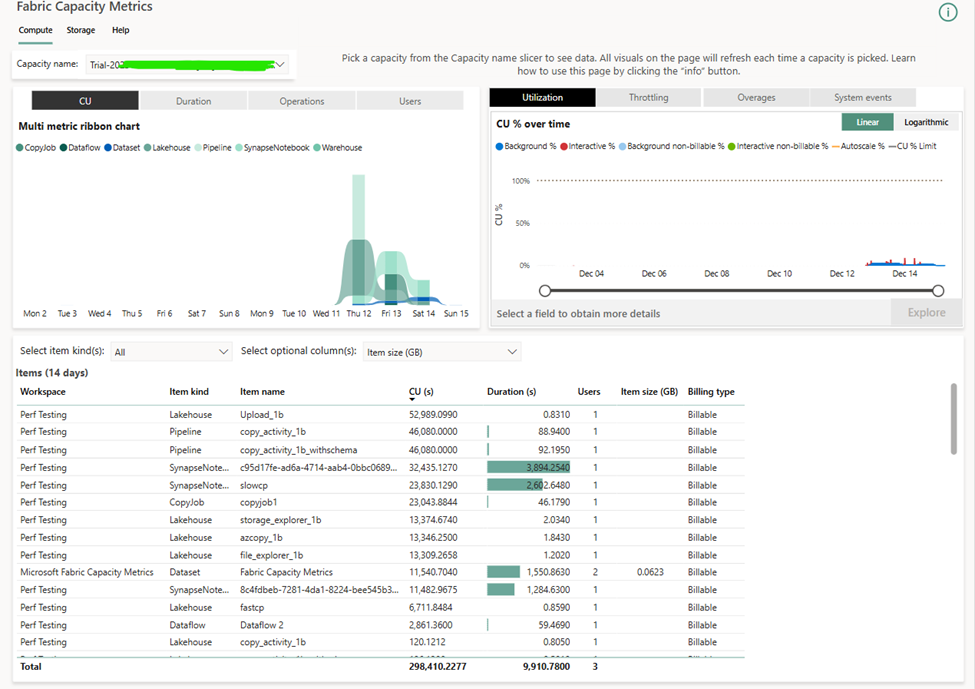
In general, I would create a separate lakehouse for each test and a separate workspace for each run of a given test. This was tedious and inefficient, but the easiest way to get clean results from the Fabric Capacity Metrics app without automation or custom reporting. I tried to set up Will Crayger’s monitoring tool but ran into some issues and will be submitting some pull requests.
To get the CU seconds, I copied from the Power BI visual in the metrics app and tried to ignore incidental costs (like creating a SQL endpoint for a lakehouse). To get the costs, I took the price of an F2 in East US 2 ($162/mo), divided it by the number of CUs (2 CUs), and divided by the number of seconds in 30 days (30*24*60*60). This technically overestimates the costs for months with 31 days in them.
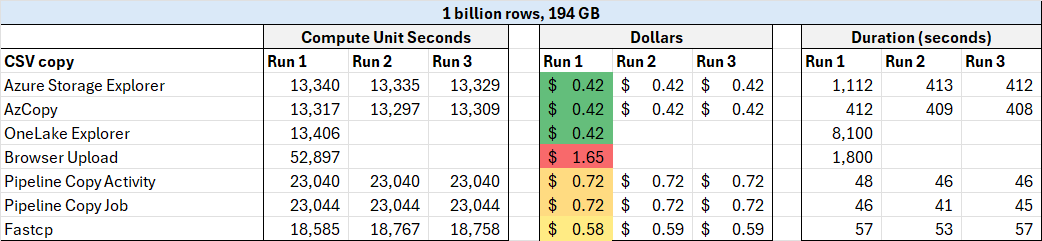
External methods of file upload (Azure Storage explorer, AZ Copy, and OneLake File Explorer) are clear winners, and browser based upload is a clear loser here. Do be aware that external methods may have external costs (i.e. Azure costs).
Data Generation process
As I mentioned, I spun up a beefy VM and ran the Contoso Data Generator, which is surprisingly well documented for a free, open source tool. You’ll need .NET 8 installed to build and run the tool. The biggest thing is that you will want to modify the config file if you want a non-standard size for your data. In my case, I wanted 1 billion rows of data (OrdersCount setting) and I limited each file to 10 million rows of data (CsvMaxOrdersPerFile setting). This technically will produce 1 billion orders so 2 actually billion sales rows when order header is combined with order lineitem. This produced 100 sales files of about 1.9 GB each.
I was hoping the temporary SSD drive included with Azure VMs was going to be enough, but it was ~30 GB if I recall, not nearly big enough. So instead, I went with Premium SSD storage instead, which has the downside of burning into my Azure Credits for as long as it exists.
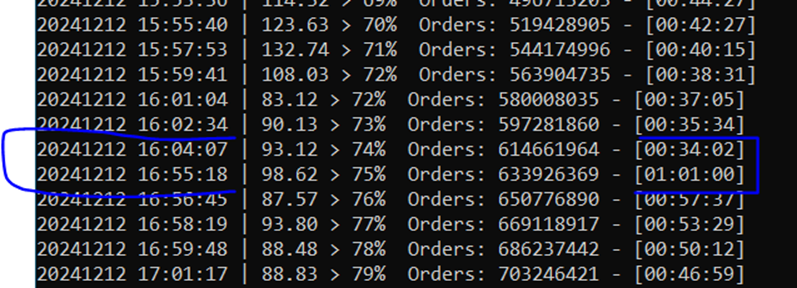
One very odd note, at around %70 percent complete, the data generation halted for no particular reason for about 45 minutes. It was only using 8 GB of the 32 GB available and was completely idle with no CPU activity. Totally bizarre. You can see it in the generation log. My best theory is it was waiting for the file system to catch up.
Lastly, I wish I was aware of how easy it was to expand the VM disk image when you allocate a terabyte of SSD. Instead, I allocated the rest of the SSD as a E drive. It was still easy to generate the data, but it added needless complication.
Thanks to James Serra’s recent blog post, I had a great starting point to identify all the ways to load data into Fabric. That said, I’d love it if he expanded it to full paragraphs since the difference between a copy activity and a copy job was not clear at all. Additionally, the Contoso generator docs list 3 ways to load the data, which was also a helpful starting point.
I stored the data on a container on Azure Blob storage with Hierarchical Namespaces turned on and the it said the Data Lake Storage endpoint is turned on by default, making it Azure Data Lake Storage Gen 2? At least I think it does, but I don’t know for sure and I have no idea how to tell.
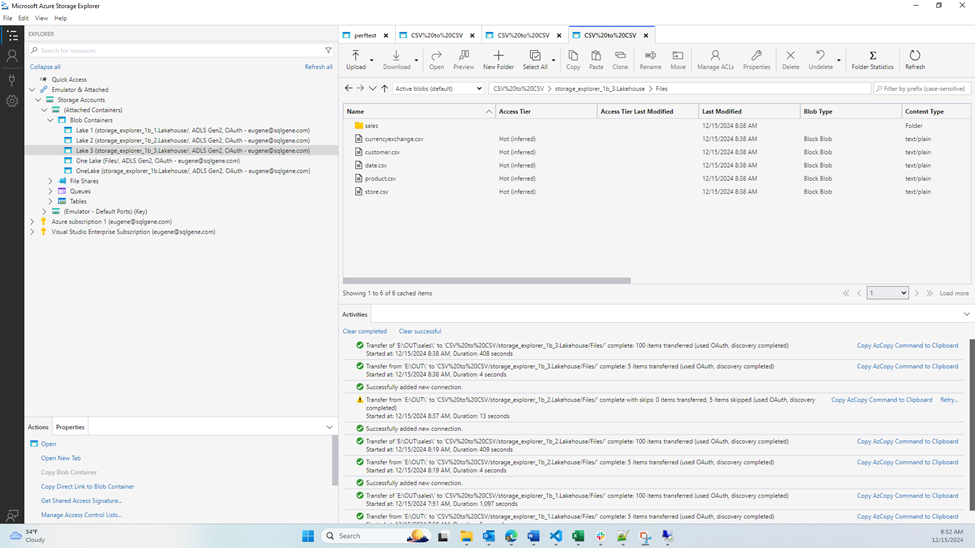
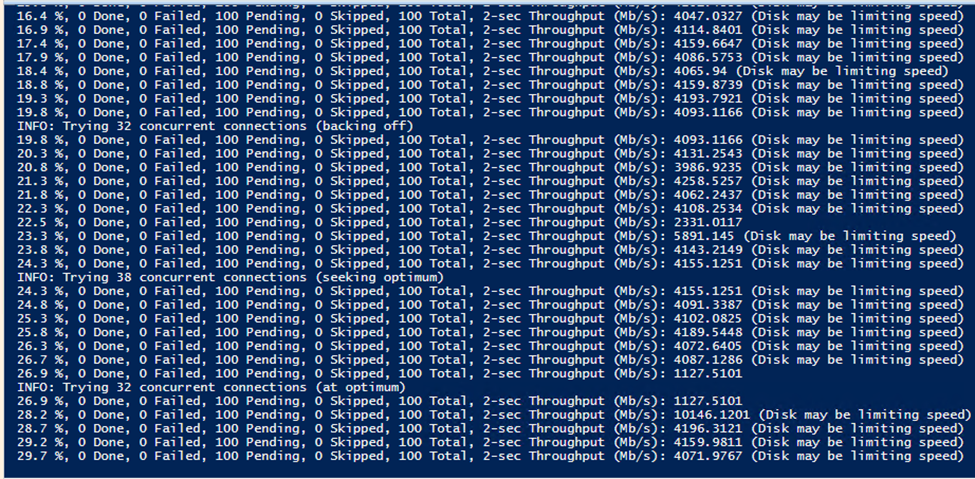
The Azure Storage Explorer is pretty neat and I was able to get it running without issue or confusion. Here are the docs for connecting to OneLake, it’s really straightforward. I did lose my RDP connection during all three of the official tests, because it maxed out IO on the disk which was the OS disk. I probably should have made a separate data disk, UGH. Bandwidth would fluctuate wildly between 2,000 and 8,000 Mbps. I suspect a separate disk would go even faster. The first time I had tested it, I swear it stayed at 5,000 Mbps and took 45 seconds, but I failed to record that.
It was also mildly surprising to find there was a deletion restriction for workspaces with capital letters in the name. Also, based on the log files in the .azcopy folder, I’m 95% sure the storage explorer is just a wrapper for AzCopy
AzCopy is also neat, but much more complicated, since it’s a command line program. Thankfully, Azure Storage Explorer let me export the AzCopy commands so I ran that instead of figuring it out myself or referencing the Contoso docs.
If you go this route, you’ll get a message like “To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ABCDE12FG to authenticate”. This authentication could be done from any computer, not just the VM, which was neat.
I got confirmation from the console output that the disk was impacting upload speeds. Whoops.
The OneLake File Explorer allows you to treat your OneLake like it was a OneDrive Folder. This was easy to set up and use, with a few minor exceptions. First, it’s not supported on Windows Server and in fact I couldn’t find a way at all to install the MISX file on Windows Server 2022. I tried to follow a guide to do that, but no luck.
The other issue is I don’t know what the heck I’m doing, so I didn’t realize I could expand the C Drive on the default image. Instead, I allocated the spare SSD space to the F drive. But when I tried to copy the files to the C drive, there wasn’t enough space, so I had them in 3 batches of 34 files.
This feature is extremely convenient but was challenging to work with at this scale. First, because it’s placed under the Users folder, both Windows search index and anti-virus were trying to scan the files. Additionally, because my files were very large, it would be quite slow when I deallocated files to free up space.
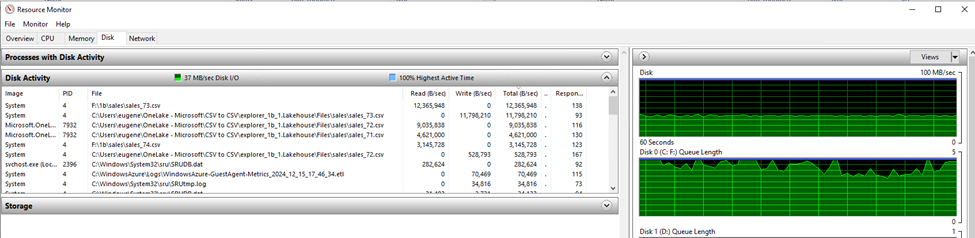
Oddly, the first batch stayed around 77 MB/s, the second was around 50 MB/s, and the last batch tanked to a speed of 12 MB/s, more than doubling the upload time. Task Manager showed disk usage at 100%, completely saturated. I tried taking a look at resource monitor but I didn’t see anything unusual. Most likely it’s just a bad idea to copy 194 GB from one drive back to itself, while deallocating the files in-between.
Browser-based file upload was the most expensive in terms of CUs but was very convenient. It was shockingly stable as well. I’ve had trouble downloading multiple large files with Edge/Chrome before, so I was surprised it uploaded one hundred 2 GB files without issue or error. It took 30 minutes, but I expected a slowdown going via browser so not complaints here. Great feature.
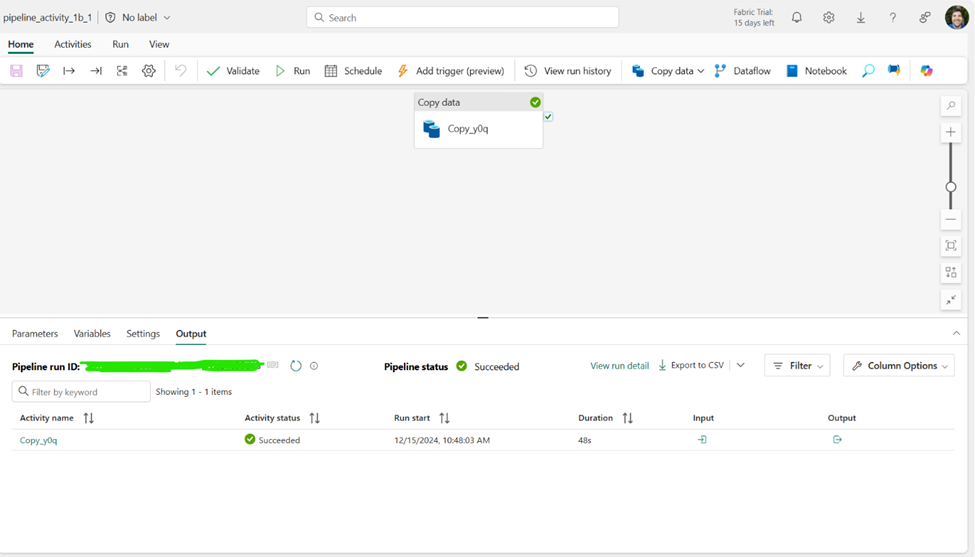
Setting up a pipeline copy activity to read from Azure Blob storage was pretty easy to do. The biggest challenge was navigating all the options without feeling overwhelmed.
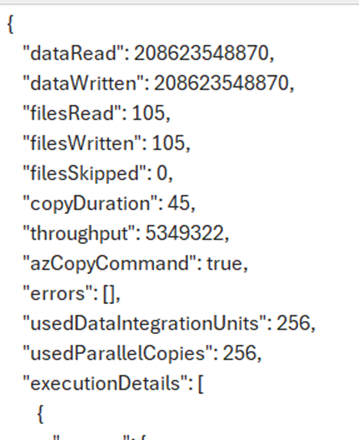
Surprisingly, there was no measurable difference in CUs between schema agnostic (binary) copy and not schema agnostic (CSV validation) copy. However, all the testing returned the same cost, so I’m guessing the costing isn’t as granular and doesn’t pick up a 2 second difference between runs.
Based on the logs it looks like it may also be using AzCopy because azCopyCommand was logged as true. It’s AzCopy all the way down apparently. The CU cost (23,040) is exactly equal to 2 times the logged copy duration (45 s) times the usedDataIntegrationUnits (256), so I suspect this is how it’s costed, but I have no way of proving it. It would explain why there was no cost variation between runs.
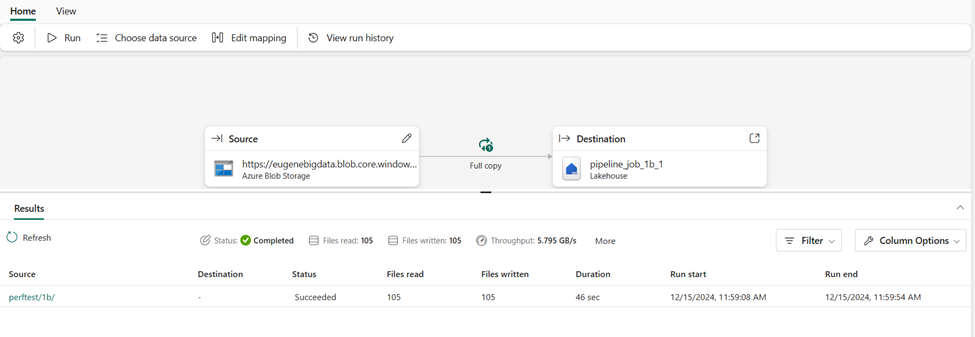
The copy job feature is just lovely. I was confused based on the name how it differed from a copy activity, but it seems to be a simpler way of copying files with fewer overwhelming options and nicer UI that clearly shows throughput, etc. The JSON code also looks very simple. Just wonderful overall.
It is in preview, so you will have to turn it on. But that’s just an admin toggle. Reitse Eskens has a nice blog post on it. My only complaint is I didn’t see a way to copy a job or import the JSON code.
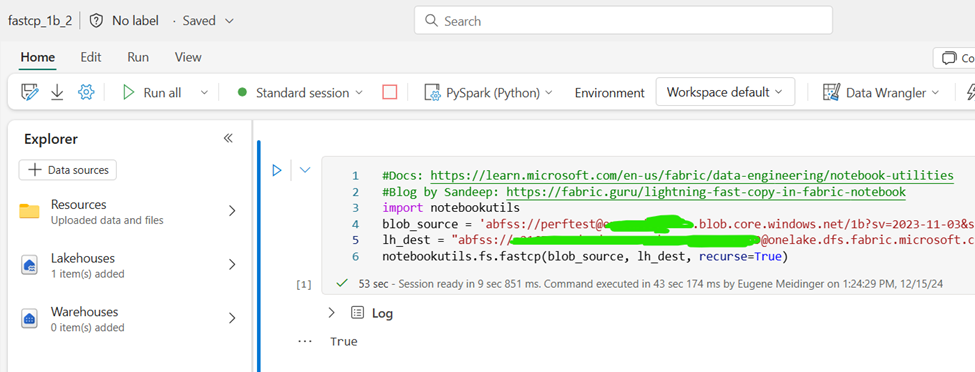
My friend Sandeep Pawar recommended trying fastcp from notbookutils in order to copy files with spark. The documentation is fairly sparse for now, but Sandeep has a short blog post that was helpful. Still, understanding the exact URL structure and how to authenticate was a challenge.
Fastcp is a wrapper for….you guessed it, AzCopy. It seems to take the same time as all the other options running AzCopy (45 seconds) + about 12 seconds for spinning up a Spark session as far as I can tell. Sandeep has told me that it also works in Python for cheaper, but when I ran the same code I got an authorization error.
Overall, I see the appeal of Spark notebooks, but one frustration was that DAX has taught me to press Alt + Enter when I need a newline, which does the exact opposite in notebooks and will instead execute a cell and make a new one.
Learnings and paper cuts
I think my biggest knowledge gap overall was in the precise difference between blob storage and ADLS storage gen 2, as well as access URLS and access methods. Multiple times I tried to generate an SAS key from the Azure Portal and got an error when I tried to use it. Once, out of frustration I copied the one from the export to AzCopy option into my spark notebook to get it to work. Another time I used the generate SAS UI in the storage explorer and that worked great.
Even trying to be aware of all the ways you can copy both CSV files as well as convert CSV to delta is quite a bit to take on. I’m not sure how anyone does it.
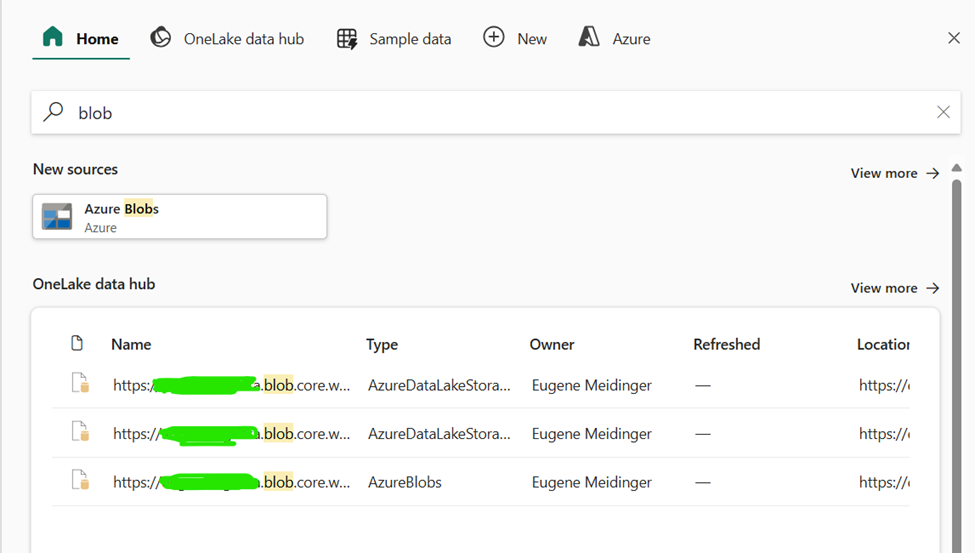
My biggest frustration with Fabric right now is around credentials management. Because I had made some different tests, if I searched for “blob”, 3 options might show up (1 blob storage, 2 ADLS).
Twice, I clicked on the wrong one (ADLS) and got an error. The icons and name are identical so the only way you can tell the difference is by “type”.
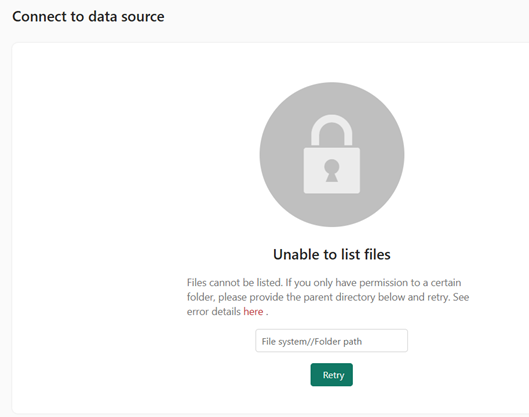
This is just so, so frustrating. Coming from Power BI, I know exactly where the data connection is because it’s embedded in the semantic model. In OneLake it appears that connections are shared and I have no idea what scope they are shared within (per user, per workspace, per domain?) and I have no idea where to go to mange them. This produces a sense of unease and being lost. It also led to frustration multiple times when I tried to add a lakehouse data source but my dataflow already had that source.
What I would love to see from the team is some sort of clear and easily accessible edit link when it pulls in an existing data source. This would be simple (I hope) and would lead to a sense of orientation, the same way that the settings section for a semantic model has similar links.
TL;DR – The fastest local format for importing data into Power BI is Parquet and then….MS Access?
The chart above shows the number of seconds it took to load X million rows of data from a given data source, according to a profiler trace and Phil Seamark’s Refresh visualizer. Parquet is a clear winner by far, with MS Access surprisingly coming in second. Sadly the 2 GB file limit stops Access from becoming the big data format of the future.
Part of the reason I wanted to do these tests is often people on Reddit will complain that their refresh is slow and their CPU is maxed out. This is almost always a sign that they are importing oodles and oodles of CSV files. I recommended trying Parquet instead of CSV, but it’s nice to have concrete proof that it’s a better file source.
For clarification, SQL_CCI means I used a clustered columnstore index on the transaction table and “JSON – no types” means all of the data was stored as text strings, even the numbers.
Finally, if you like this kind of content, let me know! This took about 2 days of configuration, prep, and testing to do. It also involved learning things that the Contoso generated dataset has Nan as a given name, which my python code interpreted as NaN and caused Power BI to throw an error. I’m considering doing something similar for Fabric data sources when Fabric DBs show up in my tenant.
Methodology
All of these test were run on my GIGABYTE – G6 KF 16″ 165HzGamingWork Laptop (don’t tell my accountants). It has an Intel i7-13620H 2.40 GHz processor, 32 GB of RAM, and a Gigabyte ag450e1024-si secondary SSD. The only time a resource seemed to be maxed out was my RAM for the 100 million row SQL test (but not for columnstore). For SQL Server, I was running SQL Server 2022.
The data I used was the Contoso generated dataset from the folks at SQLBI.com. This is a great resource if you want to do any sort of performance testing around Star Schema data. I had to manually convert it to JSON, XML, Excel and MS Access. For Excel, I had to use 3 files for the transaction table.
Initially, I was planning on testing in 10x increments from 10k rows to 100m. However, MS Access imported in under a second for both 10k and 100k, making that a useless benchmark. Trying to convert the data to more than 1m rows of data for XML, JSON, and Excel seemed like more work than it was worth. However, if someone really wants to see those numbers, I can figure it out.
For recording the times, I did an initial run to warm any caches involved. Then I ran and recorded it 3 times and reported the median time in seconds. For 100m rows, I took so long I just reported the initial run, since I didn’t want to spend half an hour importing data 4 times over.
Want to try it yourself? Here’s a bunch of the files and some sample at the 10k level:
If you want to learn more about performance tuning Power BI, consider checking out my training course. You can use code ACCESS24 to get it for $20 until Dec 6th.
Query folding is one of the most powerful tools in Power Query and Power BI. It is the automatic process of pushing down filters and other transformations back to the data source. This can dramatically improve performance for your queries.
Unfortunately, OData is not guaranteed to support query folding. According to the Power BI documentation on incremental refresh.
Most data sources that support SQL queries support query folding. However, data sources like flat files, blobs, web, and OData feeds typically do not. In cases where the filter is not supported by the datasource back-end, it cannot be pushed down. In such cases, the mashup engine compensates and applies the filter locally, which may require retrieving the full dataset from the data source.
I recently did some tests on this for the OData source for Azure Devops. When I tested with the sample Northwind database, query folding was working. I was able to see with Fiddler that my date filter was getting pushed back down.
In this case, I was manually specifying the date filter in the URL. But it should be possible to use M code to dynamically generate the URL. Another option might be to create a custom data connector for oData that supports query folding.
Promotion: Use code DAXERROR to save 10% off my course. Module 1 is free.
Sometimes, when working with DAX, you might get the following error:
The expression refers to multiple columns. Multiple columns cannot be converted to a scalar value.
This error occurs whenever the DAX engine was expecting a single value, or scalar, and instead received a table of values instead. This is an easy error to make because many DAX functions, such as FILTER, SUMMARIZE and ALL, return table values. There are three situations where this error commonly occurs:
Assigning a table value to a measure or calculated column
Forgetting to use a DAX aggregation
Treating ALL or FILTER as an action, not a function
In the rest of the post, we’ll cover each scenario and how to fix it.
Assigning a table value to a measure or calculated column
Let’s say that you were doing some analysis on the products table in the AdventureWorks sample database. In this case, maybe you want to only look at the black products. So you create a measure with the following code:
One solution to this problem is instead of assigning the code to a measure, which is intended to display a single value, you can create a calculated table instead.
To do so, go to Modeling –> New table in Power BI Desktop. Then ender the same code as before but for the calculated table. Now you will see a table filtered accordingly.
Forgetting to use a DAX aggregation
Now, what if we actually did want a single value instead of a table? Let’s say we want to count the number of black products. In that case, we could wrap our code in an aggregation function, such as COUNTROWS which can take in a table and return a single value.
This code will return the count of all products, but only if they have black as the color.
Treating ALL or FILTER as an action, not a function
Sometimes, people will try to use functions like ALL or FILTER to filter information on the report. By themselves, these functions actually return a table. However, when they are used with CALCULATE and CALCULATETABLE then you can use them to filter your data appropriately.
In the past, I’ve been skeptical about how much things like PowerShell, Devops and Docker are relevant to me personally. It makes sense if you are writing application code. It makes sense if you are managing hundreds of servers.
But I do Business Intelligence. How do you write unit tests for a report? Why do I need PowerShell when I can just hit Publish on Power BI Desktop? Do I really need Powershell if I manage 3 SQL Servers?
This year, however, there have been a number of events that have been slowly changing my mind:
Learning more about SQL Server Big Data Clusters, which depends on Kubernetes
Drew Furgiuele is doing something with a cluster of Raspberry Pi’s
I don’t know what I’m doing
I’ve talked before about how automation is a relative term. But I’d like to do some true automation, I’d like to make a script like Cody’s where I can spin up a multi-server homelab with SQL Server, Sample databases and client tools all installed.
And right now I have no idea what I’m Doing and I’m fumbling in the dark. I’ve made a github project and I’ve gotten Lability to create the virtual machines. I know I need to learn Desired State Configuration, and I can’t quite get it to work with Lability yet.
And beyond that, I have no idea what I’m doing. And that’s okay. I suspect that this is a pain a lot of people run into with devops and why they put it off. The reason I write this is to remind people is that it’s okay to suck at something.
I’ll keep y’all updated as I slowly make progress, fumbling in the dark.
Promotion: Use code DAXERROR to save 10% off my course. Module 1 is free.
Whenever you start trying to use more complicated filters in the CALCULATE or CALCULATETABLE functions in DAX, you may start to get the following error:
A function 'MAX' has been used in a True/False expression that is used as a table filter expression. This is not allowed.
The function in single quotes may vary. Instead of MAX, it could be SUM, MIN, AVERAGE or nearly anything. Sometimes, you may not even be using a function and the error will just say CALCULATE is the problem:
A function 'CALCULATE' has been used in a True/False expression that is used as a table filter expression. This is not allowed.
What causes this error?
The error is caused by using a TRUE/FALSE expression, something that evaluates to TRUE or FALSE, to filter the table in a way that CALCULATE or CALCULATETABLE doesn’t support. So the error is saying you can’t use a boolean comparison to filter your table except in very specific circumstances.
The following comparisons are not supported:
Comparing to a column to a measure. SalesHeader[TerritoryID] = [LargestTerritory]
Comparing a column to a an aggregate value. SalesHeader[TerritoryID] = MAX(TerritoryID[TerritoryID]])
Comparing a column to a What-If parameter. SalesHeader[TerritoryID] =
TerritoryParameter[TerritoryParameter Value]
In fact, you only have three options if you want to filter a column in a CALCULATE/CALCULATETABLE function:
Compare the column to a static value. SalesHeader[TerritoryID] = 6
Use variables to create a static value. VAR LargestTerritory = MAX(SalesHeader[TerritoryID])
Use a FILTER function instead of a true/false expression. FILTER(SalesHeader, SalesHeader[TerritoryID] = [LargestTerritory])
This is because CALCULATE was designed for safety and performance. Complex row based comparisons can dramatically affect performance. So, in order to do more complex comparisons, you have to take the safety feature off and use the FILTER function.
How do I fix it?
In order to fix the issue, wrap your expression in the FILTER function. To use the FILTER function, you need to pass in the table you want to filter, and then a TRUE/FALSE expression to determine which rows get return. So, let’s say we had the following code:
CALCULATE (
SUM ( SalesHeader[TotalDue] ),
SalesHeader[TerritoryID] = [LargestTerritory]
)
to use the FILTER function, we would use this:
CALCULATE (
SUM ( SalesHeader[TotalDue] ),
FILTER ( ALL ( SalesHeader[TerritoryID] ), SalesHeader[TerritoryID] = [LargestTerritory] )
)
The ALL function isn’t strictly necessary, but normally when we filter a single column in a CALCULATE function, it will undo any existing filters on that column. We use ALL here to replicate that behavior. In order to understand the specifics better, check out this article at sqlbi.com
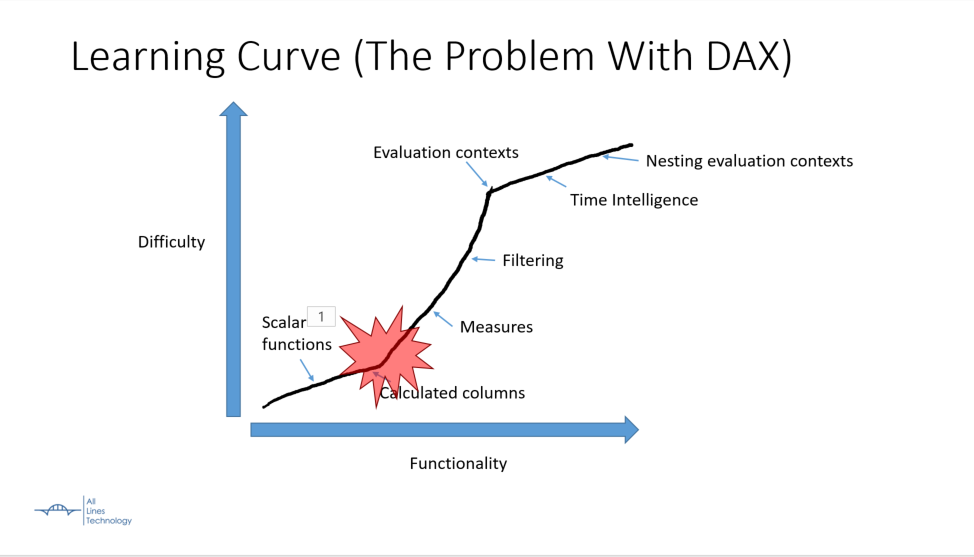
Today I’m going to be presenting on DAX for the PASS BI Virtual Group. The focus is on all the hard mental concepts of DAX. If I could sum up the talk in one picture, it would be this:
That red area is where I banged my head when learning DAX. The learning curve shoots up wildly in the middle of learning the technology, instead of a slow gentle curve. This presentation covers the middle parts that are key to understanding DAX.


![clip_image001[5]](https://www.sqlgene.com/wp-content/uploads/2019/09/clip_image0015.jpg "clip_image001[5]")